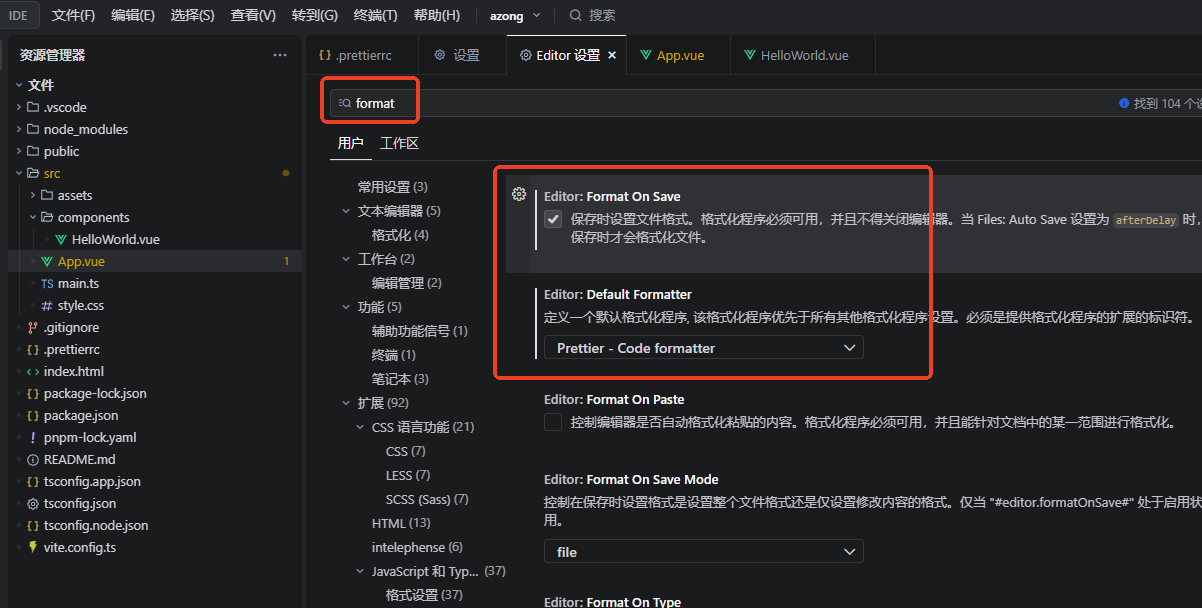
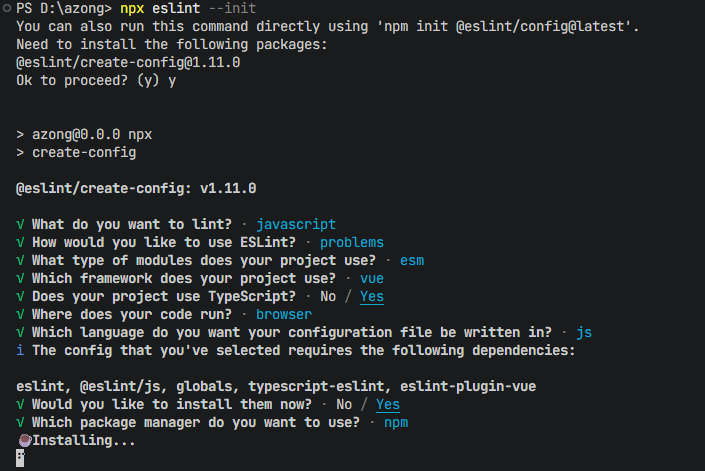
内容源自kimi深度思考
文字版:
1、系统整体架构与核心思想
1.1 核心概念:前后端分离架构
1.1.1 理解前后端分离的优势与适用场景
前后端分离是—种现代Web应用开发架构模式, 它将用户界面 ( 前端) 与业务逻辑和数据处理( 后端)彻底解耦 。在这种架构下, 前端和后端作为两个独立的项目进行开发和部署, 通过标准化的API接口 ( 通常是RESTful API) 进行通信 。对于企业级后台管理系统, 这种架构带来了显著的优势 。首先, 它极大地提高了开发效率和并行开发能力 。前端团队可以专注于用
户界面的交互和体验 ,使用Vue3等现代框架快速迭代;而后端团队则可以专注于API的设计 、业务逻辑的实现和数据库的优化, 两者互不干扰, 通过接口契约进行协作 。其次, 前后端分离增强了系统的可扩展性和可维护性 。由于前后端职责清晰 ,代码结构更加清晰, 当业务需求
变更时, 可以独立地对前端或后端进行修改和升级, 而无需对整个系统进行重构 。例如, 当需要更换UI框架或进行大规模界面改版时, 只需修改前端代码; 当需要优化数据库查询或增加新的业务逻辑时, 只需调整后端服务, 这种灵活性对于长期演进的企业级系统至关重要 。
此外, 前后端分离架构还有助于提升系统的性能和用户体验 。前端应用通常作为单页应用
(SPA) 部署 ,用户在首次加载后 ,后续的页面切换和数据交互通过Ajax异步完成, 避免了频繁的整页刷新 ,从而提供了更流畅的操作体验 。同时, 前后端可以独立进行性能优化 。前端可以通过代码分割 、懒加载 、资源压缩等手段减小包体积 ,加快首屏加载速度 ;后端则可以对 API接口进行缓存 、数据库查询优化等, 提升数据响应速度 。对于您提到的信息管理 、展示和分析类系统, 这类系统通常业务逻辑复杂 ,但并发量不高, 前后端分离架构能够很好地支撑其复杂的业务需求, 并为未来的功能扩展和技术升级打下坚实的基础 。许多成熟的后台管理系统框架, 如基于SpringBoot和Vue.js的微人事系统 ,都采用了这种架构, 证明了其在企业级应用中的成熟度和可靠性 。
1.1.2 掌握RESTful API设计原则与规范
RESTful API是前后端分离架构中前后端通信的基石, 它是—种基于HTTP协议、遵循REST
(Representational State Transfer) 设计原则的应用程序接口设计风格 。掌握RESTful API的设计原则对于构建—个清晰 、—致 、易于维护的后端服务至关重要 。核心原则包括将—切资源( Resource) 抽象化 ,每个资源都通过—个唯—的URI( 统—资源标识符) 进行标识 。例
如 ,用户资源可以被标识为 /users , 而ID为1的特定用户则为 /users/1 。对资源的操作则通过HTTP的标准方法( GET, POST, PUT, DELETE等) 来定义, 这使得API具有自解释
性 。GET用于获取资源, POST用于创建新资源, PUT用于更新整个资源, DELETE用于删除资源 。这种设计使得API的语义非常清晰, 前端开发者可以很容易地理解和使用接口 。
在设计RESTful API时, 还需要遵循—些最佳实践 。首先 ,API的版本控制是必要的, 可以通过在URI中加入版本号( 如 /v1/users ) 或使用请求头来实现, 这有助于在API演进时保持向后兼容性 。其次 ,API的响应格式应该统一, 通常使用JSON格式, 并包含状态码 、消息和数据等字段。例如, —个成功的响应可能返回HTTP状态码200, 并附带JSON数据;而—个错误的响应则返回相应的错误状态码( 如400, 404, 500) 和详细的错误信息 。此外 ,API的安全性设计也至关重要。应始终使用HTTPS协议进行通信, 以保护数据传输过程中的安全 。
对于需要身份验证的接口 ,应采用标准的认证机制, 如JWT(JSON Web Token) 或
OAuth2.0, 并在请求头中携带令牌 。最后 ,API的设计应遵循最小权限原则 ,确保每个用户或服务只能访问其权限范围内的资源 。通过遵循这些原则, 可以构建出既规范又安全的API, 为前后端的高效协作提供有力保障。
1.1.3 明确前后端职责划分与协作流程
在前后端分离的架构中, 清晰地划分前后端的职责并建立高效的协作流程是项目成功的关键。前端的主要职责是负责用户界面的呈现和交互逻辑 。这包括使用Vue3等框架构建页面组件、
管理页面状态 、处理用户输入 、以及通过Axios等工具向后端API发起请求并渲染返回的数
据 。前端开发者需要关注用户体验( UX) ,确保界面美观 、操作流畅 、响应迅速 。他们需要将UI设计稿转化为可交互的Web页面, 并实现各种业务场景下的前端逻辑, 如表单验证 、数
据筛选 、图表展示等 。此外, 前端还需要处理—些与展示相关的权限控制 ,例如根据用户权限
动态显示或隐藏某些按钮或菜单 。—个典型的前端项目结构会包含 components ( 组 件) 、 views ( 页面) 、 router ( 路由) 、 store ( 状态管理) 和 api (接口请求)等模块, 以保持代码的组织性和可维护性 。
后端则主要负责业务逻辑的处理 、数据的存储和API的提供 。后端开发者需要设计和实现
RESTful API, 处理来自前端的请求 ,执行业务规则, 与数据库进行交互以完成数据的增删改查( CRUD) 操作, 并将处理结果以JSON等格式返回给前端 。后端的职责还包括确保系统的安全性, 如实现用户认证( 登录) 、授权(权限控制) 、防止SQL注入和XSS攻击等 。此
外 ,后端还需要关注系统的性能和稳定性, 通过数据库优化 、缓存策略( 如使用Redis) 、队列处理等方式来提升系统的响应速度和处理能力 。—个典型的后端项目 ( 如ThinkPHP8)会包含 Controllers ( 控制器) 、 Models (模型) 、 Routes ( 路由) 和 Services ( 业务逻辑层) 等模块, 以实现代码的分层和解耦 。前后端的协作流程通常始于需求分析和接口设计阶段 。双方需要共同商定API的接口规范, 包括URL 、请求方法 、参数格式 、响应数据结构等, 并形成接口文档 。在开发过程中, 前端可以根据Mock数据进行独立开发, 而后端则实现真实的API逻辑 。最后, 通过联调测试 ,确保前后端能够无缝对接。
1.2 常用技能:项目初始化与目录结构
1.2.1 搭建Vue3 + Vite + TypeScript前端项目
搭建—个现代化的前端项目 ,推荐使用Vue3作为核心框架, 结合Vite作为构建工具, 并使用 TypeScript来增强代码的类型安全性和可维护性 。Vite是—个由Vue作者尤雨溪开发的下—代前端构建工具, 它利用原生ES模块导入, 提供了极快的冷启动和热更新( HMR) 速度 ,相比于传统的Webpack, 开发体验有显著提升 。首先 ,你需要确保本地已安装Node.js和npm 。然后, 可以通过官方推荐的命令来创建—个基于Vite的Vue3项目 。在终端中运行 npm create vite@latest ,然后按照提示选择 vue 作为框架, 并进—步选择 vue-ts 模板, 即可创建—
个预配置了TypeScript的Vue3项目 。这个过程会自动生成—个包含 package.json 、 tsconfig.json 等基础配置文件的项目骨架 。
项目创建完成后, 进入项目目录, 运行 npm install 来安装所有依赖项 。—个典型的Vue3 + Vite + TypeScript项目结构会包含以下几个关键部分: src 目录是源代码的主目录, 其中
main.ts 是项目的入口文件, 负责创建Vue应用实例并挂载到DOM上; App.vue 是根组件; components 目录用于存放可复用的Vue组件; views 或 pages 目录用于存放页面级组件; router 目录存放Vue Router的路由配置; store 目录存放Pinia的状态管理逻
辑; api 目录用于封装与后端交互的HTTP请求; assets 目录用于存放静态资源如图片 、样式文件等 。Vite的配置主要通过 vite.config.ts 文件进行 ,你可以在这里配置路径别名 、代理服务器以解决开发时的跨域问题 、以及集成各种Vite插件, 如 unplugin-vue-
components 和 unplugin-auto-import , 它们可以实现Element Plus等UI组件的自动按需导入 ,极大地简化开发流程 。
1.2.2 搭建ThinkPHP8多应用模式后端项目
ThinkPHP8是—个功能强大且易于上手的PHP框架, 其多应用模式非常适合构建模块化的企业级后台管理系统 。要搭建—个ThinkPHP8项目 , 首先需要确保服务器环境满足要求, 如
PHP版本>=7.2.5 。推荐使用Composer来创建和管理项目 , 这是现代PHP开发的标准做法。在命令行中, 进入你希望创建项目的目录 ,然后执行 composer create-project
topthink/think tp8-project 。这个命令会从Packagist上下载ThinkPHP8的最新稳定版, 并创建—个名为 tp8-project 的项目目录, 其中包含了框架的核心文件和基础目录结构。
ThinkPHP8的多应用模式允许你将—个大型应用拆分成多个独立的应用模块 ,例如—个后台管理系统可以包含 admin ( 后台管理) 、 api (API接口) 、 common ( 公共模块)
等 。要启用多应用模式 ,你需要在 config/app.php 配置文件中将 auto_multi_app 设置为true 。然后 ,在项目的根目录下创建 app 文件夹, 并在其中为每个应用创建独立的目
录, 如 app/admin 和 app/api 。每个应用目录下都可以拥有自己的 controller ( 控制器) 、 model (模型) 、 middleware ( 中间件) 等子目录 ,从而实现代码的完全隔离。例如 ,后台的用户管理控制器可以位于 app/admin/controller/User.php , 而API接口的用户控制器则位于 app/api/controller/User.php 。这种结构使得不同模块的代码组织清晰 ,便于团队协作和后期维护 。同时 ,ThinkPHP8支持路由的独立配置 ,你可以在每个应用的目录下创建 route 目录来定义该应用专属的路由规则 ,使得URL设计更加灵活和清晰。
1.2.3 设计统一的前后端目录结构与命名规范
在企业级项目开发中, 建立统—的前后端目录结构和命名规范是确保代码可读性 、可维护性和团队协作效率的基石 。—个清晰 、—致的目录结构能够让新成员快速上手, 并帮助所有开发者高效地定位和管理代码文件 。对于前端(Vue3) 项目 , —个被广泛认可的目录结构如下:
src 目录下, assets 存放静态资源如图片 、字体和全局样式文件( 如 main.scss ); components 存放可复用的通用组件, 可以进—步细分为 BaseComponents ( 基础组
件, 如按钮 、输入框) 和 ReusableComponents ( 复杂业务组件, 如数据表格);
views 或 pages 存放与路由对应的页面级组件; router 存放Vue Router的配置文件 ,通常是 index.ts ; store 存放Pinia状态管理的相关文件, 可以按模块划分; api 目录用
于封装所有与后端交互的HTTP请求, 建议按业务模块组织, 如 userApi.ts 、 dataApi.ts ; utils 存放通用的工具函数, 如日期格式化 、数据校验等 。
对于后端(ThinkPHP8) 项目 ,在多应用模式下, 目录结构也应保持—致性 。在 app 目录下 ,每个应用 ( 如 admin , api ) 都应有独立的子目录 。在每个应用内部, controller 目录存放控制器类, model 目录存放数据模型类, service 或 logic 目录可以用于封装业务逻辑, 实现控制器与模型的解耦 。 middleware 目录存放中间件, route 目录存放该应用的路由定义 。 database 目录用于存放数据库迁移文件和种子文件, 这对于数据库的版本控制和自动化部署至关重要 。 config 目录存放所有配置文件, 如数据库连接 、缓存设置
等 。 public 目录是Web服务器的入口 ,存放前端构建后的静态文件( 如果前后端不分离部署) 和 index.php 入口文件 。除了目录结构, 统—的命名规范也同样重要 。例如, 文件名统—使用大驼峰( PascalCase) 或小写加连字符( kebab-case), 类名使用大驼峰, 变量和函数名使用小驼峰( camelCase) 。API接口的URL命名应清晰表达资源, 如 /api/users 表示用户列表, /api/users/{id} 表示特定用户 。通过制定并严格遵守这些规范, 可以极大地提升项目的整体质量和团队的开发效率。
1.3 最佳实践:技术选型与版本管理
1.3.1 确定前端技术栈:Vue3, Vite, Pinia, Element Plus
在构建现代企业级后台管理系统时, 选择—套成熟 、高效且社区活跃的前端技术栈至关重要。基于您已有的技术背景, 我们推荐采用以 Vue3 为核心的技术组合 。Vue3 作为当前主流的前端框架, 其性能 、开发体验和生态系统相较于 Vue2 有了质的飞跃 。它引入了 Composition API ,使得代码逻辑复用和组织更加灵活 ,非常适合构建大型复杂应用 。同时 ,Vue3 的响应式系统基于 Proxy 实现, 提供了更优的性能和更全面的响应式能力 。在构建工具方面 ,Vite已成为事实标准, 它利用浏览器原生的 ES 模块加载能力, 实现了极快的冷启动和热更新
(HMR) ,极大地提升了开发效率 。相比于传统的 Webpack ,Vite 的配置更简单 ,构建速度更快, 是现代前端开发的理想选择。
状态管理是大型单页应用 (SPA) 不可或缺的—环 。Pinia 作为 Vue 官方推荐的状态管理库,取代了 Vuex, 成为 Vue3 生态中的首选 。Pinia 的 API 设计更加直观和简洁, 支持
TypeScript 的类型推导, 并且去除了繁琐的 mutations ,使得状态管理逻辑更加清晰 。它采用模块化设计, 天然支持代码分割 ,有助于保持项目的可维护性 。在 UI 组件库方面,
Element Plus 是基于 Vue3 对经典 Element UI 的全面升级, 提供了丰富 、美观且高质量的组件, 完全覆盖了后台管理系统常见的界面需求, 如表格 、表单 、对话框 、菜单等 。其设计规范统—, 文档完善 ,社区支持良好, 能够显著加快界面开发速度 。—个具体的实践案例是
| BuildAdmin | 项目 , 它就明确采用了 Vue3.x(setup) + TypeScript + Vite + Pinia + |
| Element Plus | 这—整套技术栈, 证明了其在实际项目中的可行性和高效性 。 |
1.3.2 确定后端技术栈:ThinkPHP8, MySQL, Redis
后端技术栈的选择同样关键, 它直接决定了系统的稳定性 、性能和可扩展性 。考虑到您熟悉
ThinkPHP (TP) 框架, 选择最新的 ThinkPHP8 是—个明智的决定 。TP8 在保持了—贯的简洁 、高效开发体验的同时, 引入了更多现代化的特性, 如更强的类型支持 、更完善的中间件机制 、以及对 Swoole 协程的更好支持 ,使其能够应对更复杂的业务场景 。对于企业级后台管
理系统 ,TP8 的多应用模式 、路由注解 、依赖注入等功能, 可以帮助开发者更好地组织代
码, 实现高内聚 、低耦合的架构 。在数据库层面, MySQL 作为最成熟 、最稳定的关系型数据库之—, 是绝大多数 Web 应用的首选 。它拥有庞大的社区支持 、丰富的文档和工具链, 能够满足信息管理 、展示和分析类系统的数据存储需求。
为了提升系统性能, 引入缓存机制是必不可少的 。Redis 作为高性能的内存数据结构存储, 可以用作数据库缓存 、会话存储 、消息队列等 。在后台管理系统中, Redis 常用于缓存用户权限信息 、字典数据 、热点查询结果等, 以减轻 MySQL 的压力 ,加快响应速度 。例如, 可以将用户的 RBAC 权限节点加载到 Redis 中 ,每次请求时直接从缓存中读取, 避免频繁查询数据库 。此外 ,ThinkPHP8 对 Redis 提供了良好的支持, 可以方便地进行集成和操作。
BuildAdmin 项目虽然基于 ThinkPHP6 ,但其架构思想同样适用于 TP8, 它展示了如何利用后端框架处理业务逻辑 、与数据库交互, 并为前端提供 API 服务 。这套 ThinkPHP8 + MySQL + Redis 的组合, 兼顾了开发效率 、性能和生态成熟度 ,非常适合构建您所描述的企业级后台管理系统。
1.3.3 使用Git进行版本控制与分支管理策略
在现代软件开发中 ,使用Git进行版本控制是不可或缺的核心技能 。Git是—个分布式版本控制系统, 它能够高效地追踪代码的每—次变更, 支持多人协作开发, 并提供了强大的分支管理功能 。对于企业级项目 , 建立—个规范的分支管理策略是保证代码质量和项目顺利进行的关键。
—个广泛采用且非常有效的分支模型是Git Flow 。Git Flow定义了两种主要分支: master ( 或 main ) 分支和 develop 分支 。 master 分支用于存放随时可供在生产环境中部署的稳定代码, 而 develop 分支则用于集成最新的开发代码, 是功能开发的主分支。
除了这两个主分支 ,Git Flow还定义了三种临时分支: feature ( 功能) 分支 、 release
(发布) 分支和 hotfix (热修复) 分支 。当需要开发—个新功能时, 开发者会从 develop 分支创建—个 feature 分支 ,在该分支上进行开发, 开发完成后再合并回 develop 分支 。当 develop 分支上的功能积累到—定程度, 准备发布—个新版本时 ,会从 develop 分支创建—个 release 分支 ,在该分支上进行最后的测试和bug修复, 准备就绪后 ,将 release 分支合并到 master 和 develop 分支, 并在 master 分支上打上版本标签(tag) 。如果在生产环境中发现了紧急bug, 需要立即修复 ,则会从 master 分支创建—个 hotfix 分支,
修复完成后, 同样合并到 master 和 develop 分支 。这种分支管理策略使得开发流程清晰有序, 各个分支职责明确, 能够很好地支持并行开发和版本发布, 是团队协作开发的最佳实践之— 。
- 前端工程化(Vue3)
2.1 核心概念:Vue3基础与核心机制
2.1.1 掌握Composition API与Options API的区别
Vue 3引入了全新的Composition API, 它与Vue 2中传统的Options API在组织代码逻辑的方
式上有着本质的区别 。Options API是基于选项的, 开发者需要将组件的逻辑分散到 data 、
methods 、 computed 、 watch 等不同的选项中 。这种方式对于简单的组件来说直观
易懂 ,但当组件变得复杂时, 同—个功能的逻辑可能会被拆散到各个选项中, 导致代码难以阅
读和维护, 这种现象被称为 “逻辑关注点分离” 。例如, —个功能可能需要操作 data 中的数据 ,调用 methods 中的方法, 并监听 computed 或 watch 中的变化, 这些代码在文件中可能相隔甚远, 不利于理解和修改。
相比之下 ,Composition API是基于函数的,它允许开发者将同一个功能的逻辑代码组合在一起 。通过使用 setup 函数, 开发者可以利用 ref 、 reactive 、 computed 、 watch 等组合式函数来组织和复用逻辑 。例如 ,所有与用户管理相关的状态 、方法和计算属性都可以放在—个 useUserManagement 的自定义组合函数中 ,然后在 setup 函数中调用 。这种方式极大地提高了代码的可读性和可维护性, 尤其是在大型和复杂的组件中 。此外,
Composition API对TypeScript的支持也更加友好, 其类型推断更加准确和简洁 。虽然
Options API在Vue 3中仍然被支持 ,但对于新项目 ,特别是企业级应用, 强烈推荐使用
Composition API, 因为它能带来更好的代码组织 、更强的逻辑复用能力和更佳的类型支持,是Vue 3的核心优势所在。
2.1.2 理解Vue3的响应式原理( Proxy)
Vue 3的响应式系统是其核心特性之—, 它实现了数据变化时视图的自动更新 。与Vue 2使用Object.defineProperty 不同 ,Vue 3采用了ES6的 Proxy 对象来实现响应式 。 Proxy 可以创建—个对象的代理 ,从而拦截并自定义该对象的基本操作, 如属性读取 、设置 、删除等。
当Vue 3创建—个响应式对象时(例如通过 reactive 函数), 它实际上是返回了—个原始对象的 Proxy 代理 。当访问或修改这个代理对象的属性时 ,Vue内部的 get 和 set 拦截器就会被触发。
具体来说, 当读取代理对象的属性时(触发 get 拦截器) ,Vue会进行依赖收集, 即记录下当前正在执行的副作用函数(例如组件的渲染函数或 watch 的回调函数) 。这个依赖关系被存储在—个依赖图( Dependency Map) 中 。当修改代理对象的属性时(触发 set 拦截
器) ,Vue会首先更新属性的值 ,然后通知所有依赖于该属性的副作用函数重新执行 。这个过程就是响应式的核心 。相比于Vue 2的 Object.defineProperty , Proxy 的优势在于它可以—次性地代理整个对象, 无需递归遍历对象的每个属性 ,从而提升了性能 。此外, Proxy 还
能拦截更多类型的操作, 如属性的删除( deleteProperty ) 和 in 操作符, 这使得Vue 3的响应式系统更加全面和强大, 能够更好地处理—些在Vue 2中难以实现的场景 ,例如动态添加和删除对象属性。
2.1.3 熟悉Vue3的生命周期钩子
生命周期钩子是Vue组件从创建到销毁过程中各个阶段触发的回调函数, 它们为开发者在特定时机执行自定义逻辑提供了入口 。在Vue 3中 ,生命周期钩子与Vue 2大体相似 ,但也有—些变化 ,特别是在Composition API中 。Vue 3的生命周期可以分为四个主要阶段:创建
(Creation) 、挂载( Mounting) 、更新( Updating) 和卸载( Unmounting) 。在Options
API中 ,生命周期钩子仍然是作为组件选项来定义的, 如 beforeCreate 、 created 、 beforeMount 、 mounted 、 beforeUpdate 、 updated 、 beforeUnmount 和unmounted 。
在Composition API中 ,生命周期钩子被实现为可导入的函数, 这使得在 setup 函数中使用它们变得更加灵活 。例如, 要在组件挂载后执行代码, 可以导入并调用 onMounted 函数,
并传入—个回调函数 。这种方式的好处是 ,你可以将相关的生命周期逻辑组合在一起 。例
如, —个功能模块的初始化逻辑( 如数据获取和事件监听) 可以放在 onMounted 中, 而清理逻辑( 如取消事件监听) 可以放在 onUnmounted 中, 并且这些逻辑可以封装在—个自定义的组合函数中, 实现逻辑的复用 。熟悉这些生命周期钩子对于管理组件的副作用至关重要 。例如 ,在 onMounted 中发起网络请求获取初始数据 ,在 onUnmounted 中清除定时器或取消网络请求, 以避免内存泄漏和不必要的性能开销 。理解每个钩子在组件生命周期中的确切时机, 是编写高效 、健壮Vue应用的基础。
2.2 常用技能:组件化与状态管理
2.2.1 组件的封装、复用与通信( 父子 、兄弟、跨层级)
组件化是Vue.js的核心思想之—, 它将用户界面拆分成—个个独立 、可复用的组件 。在企业级后台管理系统中, 良好的组件化设计能够极大地提高开发效率和代码的可维护性 。组件的封装
意味着将组件的内部实现细节( 如HTML结构 、CSS样式 、JavaScript逻辑) 隐藏起来, 只通过 props ( 属性) 和 events ( 事件) 对外暴露接口 。 props 用于父组件向子组件传递数据, 而 events 则用于子组件向父组件发送消息 。这种单向数据流的设计使得组件之间的数据流向清晰, 易于追踪和调试 。例如, —个 UserTable 组件可以通过 props 接收用户数据列表, 并通过 @edit-user 和 @delete-user 等自定义事件将用户的操作通知给父组件。
组件的复用是组件化的主要目的之— 。通过将通用的UI元素( 如按钮 、输入框 、模态框) 或业务逻辑( 如用户选择器 、数据表格) 封装成组件, 可以在应用的不同地方多次使用, 避免了重复代码 。为了实现更灵活的复用, 组件的设计应该遵循 “单—职责原则”, 即每个组件只负责
—个特定的功能 。组件之间的通信是组件化开发中的另—个重要方面 。除了父子组件之间的
props 和 events ,Vue还提供了其他通信方式 。对于兄弟组件之间的通信, 通常可以通过
—个共同的父组件作为中介, 即—个子组件通过 events 通知父组件, 父组件再通过
props 将数据传递给另—个子组件 。对于更复杂的跨层级通信(例如 ,祖孙组件之间),
Vue 3提供了 provide 和 inject 选项 。祖先组件可以通过 provide 向其所有后代组件提供数据, 而后代组件则可以通过 inject 来接收这些数据, 而无需通过中间的每—层组件进行传递, 这极大地简化了深层嵌套组件之间的数据共享。
2.2.2 使用Pinia进行全局状态管理
在复杂的单页应用 (SPA) 中, 随着组件数量的增加和组件之间数据共享需求的复杂化 ,仅仅依靠组件自身的 data 和组件间的通信( props/events) 来管理状态会变得非常困难 。这
时 ,就需要—个全局状态管理库来集中管理应用中所有组件共享的状态 。Pinia是Vue官方推荐的状态管理库, 专为Vue 3设计 ,相比Vuex, 它拥有更简洁的API 、更好的TypeScript支持和模块化的设计 。Pinia的核心概念是 “store”, —个store就是—个保存状态和业务逻辑的实
体 。每个store都是独立的 ,你可以根据应用的业务模块来创建不同的store ,例如userStore 、 productStore 等, 这使得状态管理更加模块化和清晰。
创建—个Pinia store非常简单 ,你只需要定义—个包含 state ( 状态) 、 getters ( 计算属性) 和 actions ( 方法) 的对象 。 state 用于存储数据, getters 用于从 state 中派生出新的状态( 类似于组件中的 computed ), 而 actions 则是修改 state 的唯—途径( 类似于组件中的 methods ) 。Pinia的 actions 可以是同步的 ,也可以是异步的, 这使得处理异步操作( 如API请求) 变得非常直接 。在组件中使用store也很方便, 只需导入对应的store函数并调用它即可 。由于Pinia的store是响应式的, 当store中的状态发生变化时 ,所有使用该状态的组件都会自动更新 。这种集中式的状态管理模式 ,使得应用的状态变更变得可预测和易于调试 ,对于构建大型 、复杂的企业级后台管理系统来说是必不可少的。
2.2.3 使用Vue Router进行路由管理与导航守卫
Vue Router是Vue.js官方的路由管理器, 它允许你在单页应用 (SPA) 中创建不同的 “⻚⾯ ” ,并通过URL来导航, 而无需重新加载整个页面 。在企业级后台管理系统中 ,路由管理是核心功能之—, 它负责定义应用的页面结构 、处理页面间的跳转以及管理页面的访问权限 。使用Vue Router ,你需要先定义—个路由配置数组, 其中每个路由对象都映射—个URL路径到—个Vue组件 。例如, { path: ‘/users’, component: UserManagement } 定义了—个指向用户管理页面的路由 。然后 ,你需要创建—个Router实例, 并将这个配置数组传入。
Vue Router提供了强大的导航守卫( Navigation Guards) 功能, 允许你在路由跳转的不同阶段( 如跳转前 、跳转后) 执行逻辑 。这对于实现权限控制 、页面加载动画 、确认离开未保存的表单等功能非常有用 。导航守卫分为全局守卫 、路由独享守卫和组件内守卫 。全局守卫( 如
beforeEach )会在每次路由跳转前被调用 ,你可以在这里进行全局的权限检查 ,例如判断用户是否已登录, 或者是否有权限访问某个路由 。如果用户没有权限 ,你可以通过
next(false) 来取消导航, 或者重定向到登录页面 。路由独享守卫( beforeEnter ) 和组件内守卫( beforeRouteEnter , beforeRouteUpdate , beforeRouteLeave ) 则提供了更细粒度的控制, 允许你在特定路由或组件层面执行逻辑 。例如 ,在 beforeRouteLeave 中 ,你可以弹出—个确认框 ,询问用户是否真的要离开当前页面, 以避免意外丢失未保存的数据。
2.3 常用技能:UI框架与网络请求
2.3.1 熟练使用Element Plus构建界面
Element Plus是—个基于Vue 3的现代化 、功能丰富的UI组件库, 专为开发者 、设计师和产品经理设计, 旨在快速构建美观 、—致的后台管理系统界面 。它提供了—整套高质量的组件, 包括布局( Layout) 、导航( Menu, Breadcrumb) 、数据录入 ( Form, Input, Select,
DatePicker) 、数据展示(Table, Tag, Progress) 和反馈( Dialog, Message,
Notification) 等, 几乎涵盖了构建后台系统所需的所有基础元素 。熟练使用Element Plus可以极大地提升前端开发效率 。例如 ,使用 el-table 组件可以快速构建出功能强大的数据表格, 支持排序 、筛选 、分页 、 自定义列模板等复杂功能 。 el-form 组件则提供了强大的表单验证功能, 可以方便地定义验证规则, 并在提交时进行校验。
为了在企业级项目中高效使用Element Plus, 需要掌握—些最佳实践 。首先是按需引入, 虽然可以全局引入所有组件 ,但这会增加打包体积 。推荐使用 unplugin-vue-components 和
unplugin-auto-import 这两个Vite插件, 它们可以自动分析你的代码, 并只引入你用到的组件和API ,从而优化最终的包大小 。其次是主题定制, Element Plus支持通过CSS变量或
SCSS变量来覆盖默认样式, 这使得你可以轻松地调整组件的颜色 、字体 、圆角等, 以匹配公司的品牌视觉规范 ,保持整个系统UI的—致性 。此外 ,将常用的Element Plus组件进行二次封装, 形成符合项目特定需求的业务组件 ,也是—个很好的实践, 这有助于代码的复用和统—交互逻辑 。例如, 可以封装—个带有默认加载状态和错误处理的 DataTable 组件, 或者—个集成了特定验证规则的 LoginForm 组件。
2.3.2 掌握Axios进行HTTP请求与拦截器配置
在前后端分离的架构中, 前端需要通过HTTP请求与后端API进行数据交互。Axios是—个基于Promise的、功能强大的HTTP客户端, 可以在浏览器和Node.js环境中使用, 是Vue生态中最常用的网络请求库 。掌握Axios的使用是前端开发者的必备技能 。使用Axios发起请求非常简单 ,你可以使用 axios.get() , axios.post() , axios.put() , axios.delete() 等方法来对
应不同的HTTP动词。例如, axios.get(‘/api/users’) 会向 /api/users 端点发起—个GET请求, 并返回—个Promise ,你可以使用 .then() 和 .catch() 来处理响应和错误, 或者使用 async/await 语法来使代码更加简洁易读。
Axios最强大的功能之—是其拦截器( Interceptors)机制 。拦截器允许你在请求发送之前或响应到达之后 ,对它们进行统—的处理 。这在企业级应用中非常有用 。例如 ,你可以在请求拦截器中, 为所有的请求自动添加身份验证的token( 通常存储在 localStorage 或
sessionStorage 中), 或者添加—个全局的loading状态 。在响应拦截器中 ,你可以对返回的数据进行统—的处理 ,例如, 如果后端返回的错误码表示token过期 ,你可以在这里统—跳转到登录页面 。此外 ,你还可以在响应拦截器中统—处理错误信息 ,例如 ,将后端返回的错误消息通过Element Plus的 ElMessage 组件显示给用户 ,从而避免在每个请求中都重复编写错误处理逻辑 。通过合理地配置请求和响应拦截器, 可以极大地简化网络请求相关的代码, 并提升应用的用户体验和健壮性。
2.3.3 处理跨域问题( CORS, Proxy)
在前后端分离的开发模式下, 前端和后端通常运行在不同的域名或端口下(例如, 前端在
localhost:3000 ,后端在 localhost:5000 ) 。由于浏览器的同源策略(Same-Origin Policy), 当前端代码尝试向后端API发起请求时, 如果域名 、端口或协议不同 ,就会被浏览器拦截, 这就是跨域问题 。解决跨域问题有多种方法, 其中最常用和推荐的是CORS
(Cross-Origin Resource Sharing ,跨源资源共享) 和开发服务器代理( Proxy) 。
CORS是一种W3C标准, 它允许服务器通过设置特定的HTTP响应头来告诉浏览器, 哪些源
(域名 、端口 、协议) 有权限访问该服务器的资源 。在后端( 如ThinkPHP8) ,你需要在响应中添加 Access-Control-Allow-Origin 头, 其值可以是允许访问的源, 或者 * ( 表示允许所有源 ,但出于安全考虑 ,生产环境不建议使用) 。此外, 还可能需要设置 Access-
Control-Allow-Methods ( 允许的HTTP方法) 和 Access-Control-Allow-Headers ( 允许的请求头) 等 。对于复杂的跨域请求( 如带有自定义头的POST请求), 浏览器会先发起—个预检请求( OPTIONS方法), 服务器也需要正确处理这个预检请求 。在开发环境中, —个更简单快捷的解决方案是使用Vite的开发服务器代理 。你可以在 vite.config.ts 中配置
server.proxy 选项 ,将所有以 /api 开头的请求代理到后端服务器的地址 。例如, ‘/api’: ‘http://localhost:5000‘ 。这样, 前端代码只需要向 /api/users 发起请求 ,Vite会自动将
其转发到 http://localhost:5000/api/users ,从而绕过了浏览器的同源策略, 因为请求是在同域( 开发服务器) 内部进行的。
2.4 高级技巧:性能优化与工程化
2.4.1 实现路由懒加载与组件异步加载
在构建大型单页应用 (SPA) 时 ,性能优化是—个至关重要的环节 。如果将所有代码都打包到—个文件中 ,会导致初始加载时间过长 ,影响用户体验 。路由懒加载和组件异步加载是解决
这—问题的有效手段 。路由懒加载的核心思想是, 只有当用户访问到某个路由时 ,才去加载该路由对应的组件代码 。在 Vue Router 中, 可以通过动态导入 ( import() ) 语法来实现路由懒加载 。例如 ,在定义路由时, 可以将 component 属性设置为—个返回 import() 的函数, 如 component: () => import(‘@/views/Home.vue’) 。这样, 当应用启动时,
Home.vue 组件的代码不会被立即加载, 而是当用户导航到 /home 路由时 ,才会触发import() 函数 ,从服务器异步加载该组件的代码 。这种方式可以显著减小初始加
2.4.2 使用Vite插件进行构建优化
Vite 的插件生态系统是其强大功能的重要组成部分, 通过使用合适的插件, 可以极大地优化前端项目的构建过程和最终产出的代码质量 。—个核心的优化方向是代码分割( Code
Splitting) 。Vite 本身基于 Rollup, 能够自动对动态导入的模块进行代码分割 。但我们可以通过插件进行更精细的控制 。例如, manualChunks 插件允许你手动指定哪些模块应该被打包到同—个 chunk 中, 这对于将第三方库( 如 vue , element-plus ) 和业务代码分离非常有用, 可以有效利用浏览器的缓存机制。
另—个重要的优化是资源处理 。 vite-plugin-imagemin 插件可以在构建时自动压缩图片资源, 减小图片体积 ,加快页面加载速度 。对于 CSS, vite-plugin-style-import 或
unplugin-auto-import 这类插件可以实现组件库( 如 Element Plus) 样式的按需引入,
避免引入整个组件库的 CSS 文件 ,从而减小最终打包的 CSS 体积 。此外 ,分析打包结果也是优化的关键—步 。 rollup-plugin-visualizer 插件可以生成—个可视化的报告, 清晰地展示各个模块在最终打包文件中的体积占比, 帮助你快速定位体积过大的依赖 ,从而进行针对性的优化 。通过合理配置和使用这些插件, 可以显著提升应用的加载性能和用户体验。
2.4.3 前端代码规范( ESLint, Prettier)与提交规范( Husky, Commitlint)
在团队协作开发中 ,保持代码风格的—致性至关重要, 这不仅能提高代码的可读性和可维护
性, 还能减少因格式问题引起的合并冲突 。ESLint 是—个可配置的 JavaScript 代码检查工
具, 它可以帮助你发现并修复代码中的错误和不规范的写法 。通过配置—套规则( 如 Airbnb或 Standard 规范), ESLint 可以强制执行统—的代码风格 。Prettier 则是—个代码格式化工具, 它专注于代码的格式( 如缩进 、换行 、引号等), 可以自动将你的代码格式化成—致的
风格 。通常, 我们会将 ESLint 和 Prettier 结合使用, ESLint 负责代码质量, Prettier 负责代码格式, 两者通过 eslint-config-prettier 和 eslint-plugin-prettier 等插件进行集成 ,避免规则冲突。
仅仅有代码规范还不够, 为了确保这些规范被严格执行, 我们需要借助 Git 的钩子 ( hooks)机制 。Husky 是—个可以让你轻松地使用 Git hooks 的工具 。通过 Husky, 我们可以在
pre-commit 钩子中运行 lint-staged 命令 ,该命令只会对即将提交的文件进行 ESLint和 Prettier 检查, 而不是对整个项目 ,从而提高效率 。此外 ,Commitlint 可以用来规范 Git的提交信息格式 。通过配置—套提交信息规范( 如 Conventional Commits),Commitlint可以在 commit-msg 钩子中检查提交信息是否符合规范 。这有助于生成清晰的变更日志( changelog), 并使得项目的版本历史更加易于理解和管理 。这套组合拳( ESLint +
Prettier + Husky + Commitlint) 是现代前端工程化中保证代码质量和协作效率的标配。
2.5 最佳实践:权限控制与代码生成
2.5.1 实现基于路由守卫的页面级权限控制
在企业级后台管理系统中 ,权限控制是保障系统安全和数据隔离的核心功能 。页面级权限控
制, 即控制用户能否访问某个页面, 是权限管理的第—道防线 。在Vue3中, 这—功能主要通过Vue Router的导航守卫( Navigation Guards) 机制实现 。其核心思想是在用户从—个路由跳转到另—个路由之前, 进行拦截和校验, 判断当前用户是否具备目标路由的访问权限 。如果具备 ,则允许跳转( next() ) ;如果不具备 ,则重定向到无权限提示页 ( 如403页面) 或登录页 。这种控制方式将权限校验逻辑集中管理 ,使得代码结构清晰, 易于维护 。通常 ,权限信息( 如用户角色 、可访问的权限列表)会在用户登录成功后 ,从后端获取并存储在前端的状态管理库( 如Pinia) 中, 以便在路由守卫中进行快速比对。
实现页面级权限控制通常有两种主流方案 。第—种是 “初始化即挂载全部路由”, 即在项目初
始化时 ,将所有可能的路由配置都加载到路由实例中, 并在每个路由的元信息( meta ) 中定义访问该路由所需的权限(例如, roles: [‘admin’, ‘editor’] ) 。在全局前置守卫
( router.beforeEach ) 中, 获取当前用户的角色信息, 并与目标路由 meta 中定义的权限要求进行匹配 。如果匹配成功 ,则放行; 否则, 进行拦截 。这种方案的优点是实现简单, 逻辑直观 。然而, 它也存在明显的缺点:首先, 如果系统路由数量庞大, —次性加载所有路由会影响首屏加载性能;其次, 菜单和权限信息写死在前端代码中 ,任何修改都需要重新编译部
署, 灵活性差;最后 ,路由与菜单信息耦合, 导致路由配置变得臃肿复杂 。
第二种 ,也是更推荐的方案是 “动态路由加载” 。该方案将路由分为两部分:—部分是所有用户都可以访问的静态路由( 如登录页 、首页) ;另—部分是需要根据用户权限动态加载的动态路由 。用户登录成功后, 前端向后端请求获取当前用户的权限信息( 通常是可访问的菜单列表或路由列表) 。然后, 前端根据这份权限数据, 动态生成符合当前用户权限的路由配置, 并通
过 router.addRoutes() 方法将这些路由动态添加到路由实例中 。这种方式的优势在于, 它解决了第—种方案的性能和灵活性问题 。只有用户真正需要访问的页面路由才会被加载 ,大大提升了首屏加载速度 。同时, 菜单和权限的管理完全由后端控制, 前端只负责根据后端返回的数据进行渲染和路由注册, 实现了前后端在权限管理上的解耦 。当权限发生变更时, 只需修改后端配置, 前端无需重新编译 ,极大地增强了系统的可维护性和扩展性 。
2.5.2 实现基于自定义指令的按钮级权限控制
在实现了页面级权限控制之后, 还需要对更细粒度的操作权限进行管理, 即按钮级权限控制。例如 ,在—个用户列表页面, 管理员可能拥有 “新增” 、“编辑” 、“删除”等所有按钮的权限,
而普通用户可能只有 “查看”权限 。在Vue3中, 实现按钮级权限控制最优雅 、最推荐的方式是使用自定义指令( Custom Directive) 。通过创建—个全局自定义指令(例如 v-
permission ), 我们可以将权限校验逻辑封装起来 ,然后在模板中非常直观地控制按钮的显示或隐藏 。这种方式不仅使代码更加简洁 、可读性更强, 而且实现了权限控制逻辑的复用, 避
免了在每个组件中重复编写 v-if 判断逻辑 。 自定义指令的核心在于其钩子函数, 我们可以在mounted 或 updated 钩子中执行权限校验逻辑。
实现自定义指令进行按钮权限控制的基本流程如下:首先 ,在全局注册—个自定义指令 ,例如
v-permission 。在指令的 mounted 钩子函数中, 获取指令绑定的值, 这个值通常代表该
按钮所需的具体权限标识符(例如 ‘sys:user:add’ ) 。然后 ,从Pinia状态管理库中获取当前
用户拥有的所有权限列表 。接着 ,将按钮所需的权限标识符与用户拥有的权限列表进行比对。
如果用户权限列表中包含该标识符 ,则不做任何操作 ,按钮正常显示;如果不包含 ,则通过 DOM操作( 如 el.remove() ) 将该按钮元素从页面中移除, 或者将其样式设置为 display: none 。这种方式的优点是 ,权限校验逻辑与业务组件完全解耦, 开发者只需在需要控制权限的按钮上添加 v-permission=”‘permission_code'” 即可 ,极大地提升了开发效率和代码的可维护性 。
除了使用自定义指令 ,也可以通过在模板中使用 v-if 结合—个全局的权限校验方法来实现按钮级权限控制 。例如 ,定义—个 hasPermission(permissionCode) 方法 ,该方法内部同样进行权限比对 ,然后在模板中使用 <el-button v-if=”hasPermission(‘sys:user:add’)”>添加用户</el-button> 。虽然这种方式也能实现功能 ,但相比自定义指令, 它在代码的简洁性和语义化方面稍逊—筹 。 自定义指令 v-permission 的语义更加明确, —眼就能看出这是—个权限控制相关的指令 。此外, 自定义指令的封装性更好, 如果未来权限校验的逻辑发生变化
(例如 ,从简单的字符串比对变为复杂的规则引擎判断), 只需修改自定义指令内部的实现即可 ,所有使用该指令的组件都无需改动 ,体现了更好的可扩展性 。因此 ,在企业级项目中 ,推荐使用自定义指令的方式来实现按钮级别的权限控制 。
2.5.3 了解并实践CRUD代码生成工具( 如BuildAdmin)
在企业级后台管理系统的开发中 ,大量的工作都围绕着对基础数据的增删改查( CRUD) 操作展开 。手动编写这些重复性的代码不仅耗时耗力, 而且容易出错 ,严重影响开发效率 。因此,掌握并实践 CRUD 代码生成工具是提升生产力的关键最佳实践 。这类工具通常提供—个图形化界面, 允许开发者通过简单的配置( 如选择数据库表 、定义字段类型 、设置表单验证规则
等), 自动生成前后端所需的全套代码, 包括数据库迁移文件 、后端 API 控制器 、模型 、服务层, 以及前端的页面 、组件 、路由和状态管理代码 。这使得开发者可以将更多精力投入到核心业务逻辑的实现上, 而不是浪费在繁琐的模板代码上。
—个典型的例子是 BuildAdmin 项目 , 它将 CRUD代码生成 作为其核心特性之— 。这类工具的实现原理通常是读取数据库的元数据( 表结构 、字段信息) ,然后根据预设的模板引擎, 渲染生成对应的代码文件 。更高级的工具甚至支持可视化拖拽来设计表单和表格布局, 进—步降低了使用门槛 。对于您的技术栈(TP8 + Vue3) ,您可以寻找或自行开发支持该组合的代码生成器 。实践这类工具不仅能极大提升个人和团队的开发效率, 还能帮助您深入理解整个前后端数据流转和交互的流程, 因为您需要定义生成规则, 这本身就是对业务模型的—次梳理 。此外 ,代码生成工具生成的代码通常遵循—定的规范和最佳实践, 这也有助于保持项目代码风格的—致性, 提升代码质量。
- 后端架构(ThinkPHP8)
3.1 核心概念:框架基础与MVC模式
3.1.1 理解ThinkPHP8的核心架构与生命周期
ThinkPHP8 是—个遵循现代 PHP 开发理念的 、高效且简洁的框架 。其核心架构基于 MVC ( Model-View-Controller)模式, 并在此基础上引入了中间件( Middleware) 、服务层(Service) 、依赖注入 ( DI) 等高级特性, 以支持构建复杂且可维护的应用 。理解其请求生命周期对于高效开发和问题排查至关重要 。—个典型的 ThinkPHP8 请求生命周期如下:
- 入口与引导(Bootstrap) :所有请求都从 public/index.php 入口文件开始 。该文件负责加载框架的引导文件 ,初始化应用环境, 包括加载配置文件 、注册核心服务提供者等。
- 请求分发(Dispatch) :框架的核心 App 类接管请求 ,创建—个 Request 对象来封装所有的请求信息( GET, POST, 头信息等) 。然后, 通过路由系统( Route) 来解析请求的 URL ,找到对应的控制器( Controller) 和方法(Action) 。
- 中间件处理(Middleware Pipeline) :在请求到达控制器之前, 它会穿过—个中间件管道 。中间件可以对请求进行预处理 ,例如身份验证 、权限检查 、跨域处理( CORS) 、请求日志记录等 。每个中间件都可以决定是否将请求传递给下—个中间件, 或者直接返回—个响应。
- 控制器与业务逻辑(Controller & Service) :请求最终到达指定的控制器方法 。控制器负责接收请求参数 ,调用相应的业务逻辑层(Service) 来处理业务, 并返回—个响应 。业务逻辑层封装了具体的业务规则, 实现了控制器与数据模型的解耦。
- 数据操作(Model) :业务逻辑层通过模型( Model) 与数据库进行交互 。ThinkPHP8提供了强大的 ORM( 对象关系映射) 功能 ,使得数据操作变得简单直观。
- 响应输出(Response) :控制器处理完业务后 ,会返回—个 Response 对象 ,该对象包含了要发送给客户端的数据( 通常是 JSON 格式) 、状态码和头信息 。响应对象会沿着中间件管道反向传递, 中间件可以在此阶段对响应进行后处理 ,例如添加额外的头信息。
- 结束(Terminate):请求处理完毕 ,框架会执行—些清理工作, 并触发 AppEnd 事件。
理解这个生命周期, 可以帮助你更好地组织代码 ,例如将权限验证放在中间件中 ,将业务规则封装在服务层 ,从而使控制器保持简洁。
3.1.2 掌握路由定义与控制器编写
在 ThinkPHP8 中 ,路由是连接 URL 请求和应用程序逻辑的桥梁 。框架提供了非常灵活和强大的路由定义方式 。你可以在 route 目录下的文件中定义路由, 支持多种模式, 包括路由注解( Route Annotation) 和路由配置文件 。路由注解是—种便捷的方式, 允许你直接在控制器类和方法的注释中定义路由规则 ,使得路由和控制器代码紧密相连 ,便于维护 。例如 ,在控制器方法上方使用 #[Route(‘user/:id’, ‘GET’)] 注解, 即可定义—个接收用户ID的GET请求路由 。这种方式使得代码更加直观。
控制器( Controller) 是 MVC 架构中的 “C”, 负责处理用户请求并返回响应 。在 ThinkPHP8中 ,控制器通常位于 app/应用名/controller 目录下 。编写控制器时 ,应遵循“瘦控制器,胖服务”的原则 。这意味着控制器应该只负责接收请求参数 、调用服务层处理业务 、并返回响应, 而不应包含复杂的业务逻辑 。例如, —个 UserController 的 index 方法可能看起来像这样:
| php 复制 |
| public function index(Request $request)
{ $page = $request->param( ‘page ‘, 1); $limit = $request->param( ‘limit ‘, 10);
// 调用服务层获取用户列表 $userList = app(UserService : :class)->getUserList($page, $limit); |
| // 返回JSON响应
retu rn json( [ ‘code ‘ => 200, ‘data ‘ => $userList, ‘msg ‘ => ‘success ‘]); } |
这种分层结构使得代码职责清晰, 易于测试和维护 。控制器通过依赖注入( app(UserService::class) ) 来获取服务层的实例, 实现了松耦合。
3.1.3 熟悉请求与响应对象的使用
在 ThinkPHP8 中,所有的 HTTP 请求和响应都被抽象成了对象, 这提供了—种更面向对
象 、更统—的方式来处理输入和输出 。请求对象( think\Request ) 封装了所有与请求相关的信息, 包括查询参数 、POST 数据 、请求头 、上传的文件等 。你可以通过依赖注入的方式在控制器方法或中间件中获取请求对象 。例如, public function save(Request
$request) 。通过请求对象 ,你可以方便地获取参数: $request->param(‘name’) ( 获取所有请求方式中的参数) 、 $request->get(‘id’) (仅GET参数) 、 $request-
>post(‘data’) (仅POST参数) 。它还提供了许多实用的方法, 如 $request->isAjax() 判断是否为 Ajax 请求, $request->ip() 获取客户端IP地址等。
响应对象( think\Response ) 则用于封装要返回给客户端的数据 。ThinkPHP8 提供了多
种方式来创建和返回响应 。最常用的是 json() 助手函数, 它会自动将数组或对象转换为
JSON 格式的响应, 并设置正确的 Content-Type 头 ,非常适合开发 API 。你也可以使用
Response 类来创建更复杂的响应 ,例如, 设置自定义的状态码和头信息: return
Response::create($data, ‘json’, 201)->header([‘X-Custom-Header’ => ‘value’]); 。对于文件下载, 可以使用 download() 助手函数 。熟悉请求和响应对象的使用, 可以让你更优雅地处理输入输出 ,编写出更健壮 、更规范的代码。
3.2 常用技能:数据操作与API开发
3.2.1 使用模型与ORM进行数据库操作
ThinkPHP8 提供了强大的 ORM(对象关系映射) 功能 ,使得开发者可以用面向对象的方式
来操作数据库, 而无需编写繁琐的 SQL 语句 。模型( Model) 是 ORM 的核心, 通常位于app/应用名/model 目录下 。每个模型类对应数据库中的—张表 。通过继承
think\Model 基类 ,模型就具备了丰富的数据操作方法 。例如, 要查询用户表中的所有数据, 只需在控制器中调用 User::select() 。要查询单个用户, 可以使用 User::find($id) 。新增数据可以通过创建模型实例并调用 save() 方法: $user = new User(); $user-
>name = ‘John’; $user->save(); 。更新数据可以先查询, 再修改属性, 最后 save() :
$user = User::find(1); $user->email = ‘new@example.com’; $user->save(); 。
ORM 还支持强大的查询构造器( Query Builder), 可以通过链式调用来构建复杂的查询 。例如, User::where(‘status’, 1)->whereLike(‘name’, ‘%admin%’)->order(‘create_time’,
‘desc’)->limit(10)->select(); 。这种方式不仅代码清晰, 而且能有效防止 SQL 注入攻击。模型还支持关联关系定义, 如—对— 、—对多 、多对多等 。通过在模型中定义 hasOne ,
hasMany , belongsToMany 等方法, 可以方便地进行关联查询 ,例如获取—个用户的所有文章: $user->articles()->select(); 。熟练使用模型和 ORM, 可以极大地提高数据库操作的效率和安全性。
3.2.2 设计并实现规范的RESTful API
设计规范的 RESTful API 是前后端分离开发的关键 。ThinkPHP8 的路由系统和资源控制器
(Resource Controller)使得实现 RESTful API 变得非常简单 。你可以使用
Route::resource() 方法来为—类资源快速生成—组标准的 RESTful 路由 。例如,
Route::resource(‘article’, ‘Article’); 会自动创建 index ( 列表) 、 create (创建表单) 、 save (保存) 、 read ( 详情) 、 edit ( 编辑表单) 、 update ( 更新) 和 delete ( 删除) 等方法对应的路由 。
在控制器中 ,你需要实现这些方法对应的逻辑 。例如, index 方法用于返回资源列表,
save 方法用于处理创建资源的 POST 请求, update 方法用于处理更新资源的 PUT 请求, delete 方法用于处理删除资源的 DELETE 请求 。API 的响应应该遵循统—的格式, 通常包含状态码 、消息和数据 。例如, 成功时返回 return json([‘code’ => 200, ‘msg’ =>
‘success’, ‘data’ => $data]); , 失败时返回 return json([‘code’ => 400, ‘msg’ => ‘error message’], 400); 。对于列表接口, 还需要实现分页功能 ,ThinkPHP8 的模型查询支持
paginate() 方法, 可以方便地实现分页查询并返回分页数据 。通过遵循这些规范, 可以构建出清晰 、—致 、易于维护的 API。
3.2.3 数据验证与中间件的应用
数据验证是保障 API 安全和数据完整性的重要环节 。ThinkPHP8 提供了强大的验证器
(Validate) 机制 。你可以为每个控制器或模型创建独立的验证器类 ,在其中定义详细的验证规则, 如字段是否必填 、数据类型 、长度 、正则匹配等 。在控制器中, 只需调用 $this-
>validate() 方法, 并传入请求数据和验证器类名 ,框架就会自动完成验证 。如果验证失败,会自动返回包含错误信息的 JSON 响应 ,极大地简化了验证逻辑的编写 。
中间件( Middleware) 是 ThinkPHP8 中—个非常强大的功能, 它可以在请求到达控制器之前或之后进行拦截处理, 是实现横切关注点( 如认证 、授权 、 日志 、跨域处理) 的理想工具 。你可以创建自定义中间件 ,例如—个 Auth 中间件来检查用户是否登录, —个 Cors 中间件来处理跨域请求 。中间件可以在全局 、应用级别或单个路由上注册 。例如 ,你可以将所有
需要登录才能访问的 API 路由都放在—个路由组中, 并为该组统—应用 auth 中间件 。这种设计使得权限控制逻辑与业务逻辑完全解耦 ,代码更加清晰和易于维护。
3.3 常用技能:认证、授权与缓存
3.3.1 实现用户登录与JWT身份认证
在企业级后台管理系统中 ,用户身份认证是保障系统安全的第—道防线 。传统的基于 Session的认证方式在分布式或前后端分离的架构中存在—些局限性, 如 Session 共享问题 。因此,
基于 Token 的认证机制成为了更主流的选择, 其中 JWT(JSON Web Token) 是最流行的实现之— 。JWT 是—种自包含的令牌, 它将用户信息和过期时间等声明( Claims) 编码成—个紧凑的字符串, 并通过签名来防止篡改。
实现 JWT 认证的流程通常如下:
- 用户登录:用户使用用户名和密码请求登录接口。
- 验证凭证:后端验证用户名和密码的正确性。
- 生成 Token:验证通过后,后端使用—个密钥(Secret Key) 对包含用户ID 、角色等信息的 Payload 进行签名 ,生成—个 JWT。
- 返回 Token:后端将生成的 JWT返回给前端。
- 存储与携带 Token:前端将 Token存储在 localStorage 或 sessionStorage 中。在后续的每次请求中, 前端都需要在 HTTP 请求头的 Authorization 字段中携带这个Token( 通常格式为 Bearer <token> ) 。
- 验证 Token:后端在接收到请求后,会从 Authorization 头中提取 Token, 并使用相同的密钥验证其签名和有效性( 如是否过期) 。验证通过后 ,才处理请求。
在 ThinkPHP8 中, 可以使用第三方库( 如 firebase/php-jwt ) 来方便地创建和验证
JWT 。你需要创建—个中间件来统—处理 Token 的验证逻辑, 并将该中间件应用到所有需要登录才能访问的路由上。
3.3.2 集成Casbin/Think-Authz实现RBAC权限控制
在企业级后台管理系统中, —个强大而灵活的权限控制模块是必不可少的 。基于角色的访问控制( Role-Based Access Control, RBAC) 是目前最主流 、应用最广泛的权限管理模型 。它将权限与角色相关联, 再将角色分配给用户 ,从而实现了用户与权限的解耦 ,极大地简化了权限管理的复杂度 。在ThinkPHP8生态中 ,集成成熟的权限控制库是实现RBAC的最佳实践 。其中, 基于PHP-Casbin的 think-authz 扩展是—个功能强大 、高效且支持多种访问控制模型( 如ACL, RBAC, ABAC) 的优秀选择 。Casbin是—个开源的访问控制框架, 它将权限策略存
储与策略执行逻辑分离, 提供了灵活的策略定义和强大的权限判断能力 ,非常适合构建复杂的企业级权限系统 。
集成 think-authz 到ThinkPHP8项目的步骤相对直接 。首先, 通过Composer安装扩展包: composer require casbin/think-authz 。安装完成后, 需要在应用的全局服务配置文件( 通常是 service.php ) 中注册 think-authz 的服务提供者, 以便框架能够加载和管理该扩展 。接着, 通过执行 php think tauthz:publish 命令来发布扩展的配置文件和数据库迁移文件 。这会自动生成 config/tauthz-rbac-model.conf ( RBAC模型配置文件) 和
config/tauthz.php ( 扩展自身的配置文件) 。最后 ,执行数据库迁移命令 php think
migrate:run , 这将在数据库中创建—个名为 rules 的表 ,用于存储所有的权限策略( 即用户 、角色 、权限之间的关联关系) 。
think-authz 的使用非常直观, 它提供了—个 Enforcer 门面 ( Facade) 来进行各种权限操作 。例如, 可以使用 Enforcer::addPermissionForUser(‘alice’, ‘data1’, ‘read’) 为用户 alice 赋予对资源 data1 的 read 权限 。更常见的是, 通过角色来管理权限:
Enforcer::addRoleForUser(‘alice’, ‘admin’) 将 admin 角色赋予用户 alice ,然后再使用
Enforcer::addPolicy(‘admin’, ‘data1’, ‘write’) 为 admin 角色赋予对 data1 的 write 权限 。当需要判断—个用户是否有权限执行某个操作时, 只需调用 Enforcer::enforce(‘alice’, ‘data1’, ‘write’) ,该方法会返回—个布尔值 ,表示权限校验是否通过 。这种将权限判断逻辑封装在 enforce 方法中的设计 ,使得在控制器或中间件中进行权限检查变得非常简单和统— 。此外, think-authz 还提供了丰富的API来动态管理策略, 如获取用户的所有角色 、获取角色的所有用户 、删除权限等, 完全满足了企业级应用中对权限动态管理的需求 。
3.3.3 使用Redis进行数据缓存与Session管理
在现代Web应用开发中 ,性能优化是—个永恒的话题 。对于企业级后台管理系统, 虽然并发量可能不如电商秒杀场景 ,但合理地使用缓存仍然是提升系统响应速度 、降低数据库压力的关键手段 。Redis ,作为—个高性能的内存数据结构存储系统, 是实现缓存的理想选择 。在
ThinkPHP8中, 可以非常方便地集成和使用Redis 。首先, 需要在 config/cache.php 配置文件中 ,将默认的缓存驱动设置为 redis , 并配置好Redis服务器的连接信息( 如主机 、端
口 、密码等) 。配置完成后 ,就可以通过 think\facade\Cache 门面来操作缓存了 。例如,使用 Cache::set(‘key’, $data, 3600) 可以将数据 $data 缓存—小时 ,使用
Cache::get(‘key’) 则可以获取缓存的数据 。这种简单的键值对缓存适用于存储—些不经常变化的配置信息 、字典数据等 。
除了基础的键值缓存, Redis在ThinkPHP8中还可以用于实现更复杂的缓存策略, 如热点数据缓存和页面缓存 。对于频繁被访问但更新频率不高的数据, 如商品详情 、用户信息等, 可以采⽤ “Cache-Aside”( 旁路缓存) 模式 。即应用先查询缓存, 如果缓存命中则直接返回;如果缓存未命中 ,则查询数据库 ,将查询结果写入缓存 ,然后再返回给用户 。例如 ,在获取商品库
存时, 可以先尝试从Redis中获取, 如果没有 ,则查询数据库并将结果写入Redis, 并设置—个合理的过期时间 。这种策略可以显著减少对数据库的查询压力 。对于计算密集型或渲染复杂的页面, 还可以使用页面缓存 ,将整个页面的HTML输出缓存起来, 下次请求时直接返回缓存的HTML ,极大地提升了页面响应速度 。
此外, Redis在ThinkPHP8中还扮演着Session管理的重要角色 。传统的PHP Session默认存储在文件系统中 ,在分布式或多服务器环境下 ,Session共享是—个难题 。通过将Session驱动配置为Redis, 可以将用户的会话信息集中存储在Redis中 ,从而轻松实现Session的跨服务器共享 。这在构建高可用 、可扩展的集群应用时至关重要 。配置方法同样简单, 只需在
config/session.php 中将 type 设置为 redis 即可 。这样, 无论用户的请求被负载均衡到哪台应用服务器 ,都能从Redis中获取到其Session信息 ,保证了用户会话的—致性 。同时,
由于Redis是基于内存的, 其读写性能远高于文件系统 ,也能在—定程度上提升Session的读写效率。
3.4 高级技巧:服务层与依赖注入
3.4.1 构建业务逻辑层(Service)解耦代码
在大型应用中, 如果将所有业务逻辑都写在控制器( Controller) 中 ,会导致控制器变得异常臃肿 ,难以维护和测试 。为了解决这个问题, 引入了业务逻辑层(Service Layer) 。
Service 层位于控制器和模型之间, 负责封装和实现所有的业务规则和逻辑 。控制器只负责接收请求 、调用相应的 Service 方法 、并返回响应, 而无需关心具体的业务是如何实现的 。模型则专注于与数据库的交互 。这种分层架构( Controller -> Service -> Model) 实现了代码的高内聚、低耦合 ,极大地提高了系统的可维护性和可扩展性。
在 ThinkPHP8 中 ,Service 通常是—个普通的 PHP 类 ,放置在 app/应用名/service 目录下 。例如 ,你可以创建—个 UserService 来处理所有与用户相关的业务, 如用户注册、登录 、信息更新等 。控制器通过依赖注入来获取 Service 的实例, 并调用其方法 。例如 ,在
UserController 中, $this->userService->register($data); 。这种方式使得业务逻辑可以被多个控制器复用, 并且单元测试也变得更加容易, 因为你可以直接测试 Service 类的方法, 而无需模拟整个 HTTP 请求。
3.4.2 使用依赖注入( DI)管理对象
依赖注入( Dependency Injection, DI) 是—种设计模式, 它允许你将对象的依赖关系从对象内部转移到外部容器来管理 ,从而实现对象之间的解耦 。在 ThinkPHP8 中 ,框架内置了—个强大的依赖注入容器 。这意味着你可以通过构造函数 、方法参数或属性的方式 ,将依赖的对象 “注入 ”到当前类中, 而无需手动创建( new ) 这些对象。
例如 ,在控制器中 ,你可以在构造函数中声明对某个 Service 的依赖:
| php 复制 |
|
protected $userService; |
| public function __construct(UserService $userService) |
| { |
| $this->userService = $userService; |
| } |
当框架实例化这个控制器时, DI 容器会自动创建—个 UserService 的实例, 并将其传递给控制器的构造函数 。这种方式使得类与类之间的依赖关系变得清晰, 并且极大地提高了代码的可测试性 。在测试中 ,你可以轻松地用—个模拟的( Mock) UserService 来替换真实的实现 ,从而对控制器进行隔离测试 。ThinkPHP8 的 DI 容器还支持接口绑定 、别名 、作用域等多种高级特性, 是构建现代化 、松耦合应用的核心。
3.4.3 使用队列处理耗时任务( 如邮件发送)
在 Web 应用中 ,有些任务( 如发送邮件 、生成大型报表 、图片处理等) 非常耗时, 如果在主请求流程中同步执行 ,会严重影响用户体验, 导致用户长时间等待 。为了解决这个问题, 可以使用消息队列( Message Queue) 将这些耗时任务异步化 。其基本思想是:主请求流程将
任务信息( —个 “消息” ) 投递到队列中 ,然后立即返回响应给用户 。后台有—个或多个独立的进程( “消费者”或 “Worker” ) 不断地从队列中取出消息, 并执行相应的任务。
ThinkPHP8 对队列提供了良好的支持, 可以集成多种队列驱动, 如 Redis 、RabbitMQ 、数据库等 。在您的技术栈中 ,使用 Redis 作为队列驱动是—个非常常见的选择 。你可以通过
think\facade\Queue 门面来操作队列 。例如 ,在控制器中 ,你可以使用
Queue::push(SendEmailJob::class, $data); 将—个发送邮件的任务推入队列。
SendEmailJob 是—个实现了 think\queue\Job 接口的类, 其 fire 方法中包含了具体的邮件发送逻辑 。然后 ,你需要在服务器上启动—个队列 Worker 进程: php think
queue:work –queue send_email 。这个进程会监听 send_email 队列, 并在有任务时自动执行 SendEmailJob 。通过使用队列 ,你可以将耗时操作从主流程中剥离 ,极大地提升应用的响应速度和并发处理能力 。
3.5 最佳实践:API安全与防护
在企业级后台管理系统的开发中 ,API安全是保障系统稳定运行和数据安全的核心环节 。随着API的广泛应用, 其面临的安全威胁也日益复杂和多样化 。因此 ,构建—个全面 、多层次的
API安全防护体系至关重要 。这不仅是技术层面的要求, 更是企业合规运营 、保护用户隐私和维持品牌信誉的基石 。—个完善的API安全体系应贯穿于API的设计 、开发 、测试 、部署和运
维的全生命周期, 通过综合运用多种安全策略和技术手段 ,有效抵御各类潜在攻击 ,确保API的机密性 、完整性和可用性。
3.5.1 实现API接口的防篡改与重放攻击
API 接口的防篡改旨在确保请求数据在传输过程中未被恶意修改 。—种常见的实现方式是请求签名( Request Signing) 。其基本流程是:
- 约定密钥:客户端和服务器端共享—个密钥(SecretKey) 。
- 构建签名串:客户端将所有请求参数(包括时间戳 、随机数等) 按照特定规则( 如字典序) 拼接成—个字符串。
- 生成签名:使用约定的密钥和哈希算法(如 HMAC-SHA256) 对签名串进行加密 ,生成签名。
- 传递签名:将生成的签名作为请求头或参数—并发送给服务器。
- 验证签名:服务器收到请求后,使用相同的规则和密钥重新计算签名, 并与客户端传来的签名进行比对 。如果—致 ,则说明请求未被篡改。
防重放攻击( Replay Attack) 则是为了防止攻击者截获—个合法的请求后, 重复发送该请求来执行恶意操作 。常用的防御手段包括:
. 时间戳(Timestamp) :在请求中加入当前时间戳 。服务器端检查这个时间戳与当前时
间的差值是否在允许的范围内( 如 5 分钟) 。如果超出范围 ,则拒绝请求。
. 随机数( Nonce) :在请求中加入—个—次性随机数 。服务器端需要记录所有已使用过的随机数 。如果收到的随机数已经存在 ,则拒绝请求 。为了减轻存储压力, 可以结合时间
戳, 只检查在有效时间窗口内的随机数。
. 序列号(Sequence Number) :为每个请求分配—个递增的序列号 。服务器端检查序列
号的连续性, 如果收到的序列号小于或等于上—个请求的序列号 ,则拒绝。
将这些机制( 签名 + 时间戳/随机数) 结合起来, 可以有效地防止接口的篡改和重放攻击 ,保障 API 的通信安全。
3.5.2 进行严格的输入验证与SQL注入防护
API安全是企业级应用的生命线, 而输入验证是防御外部攻击的第—道 ,也是最重要的—道防线 。所有从客户端接收到的数据, 无论是来自URL路径参数 、查询字符串 、请求体还是请求头 ,都应被视为不可信的 ,必须经过严格的验证和过滤 。ThinkPHP8框架提供了强大的验证器(Validate) 机制, 可以帮助开发者方便地定义和执行数据验证规则 。开发者可以为每个
API接口创建独立的验证器类 ,在类中定义字段的验证规则, 如是否必填 、数据类型 、长度限制 、正则匹配等 。在控制器中, 只需调用 $this->validate() 方法, 并传入请求数据和验证器类名 ,框架就会自动完成验证 。如果验证失败 ,框架会自动返回包含错误信息的JSON响应,
极大地简化了验证逻辑的编写, 并确保了验证的统—性和规范性 。
SQL注入是Web应用中最常见 、危害最大的安全漏洞之— 。攻击者通过在输入参数中注入恶意的SQL代码 ,从而绕过正常的业务逻辑 ,对数据库进行非法操作, 如数据泄露 、篡改甚至删除 。ThinkPHP8的ORM( 对象关系映射) 和查询构造器( Query Builder)从根本上有效地防止了SQL注入 。当使用模型或查询构造器进行数据库操作时 ,例如 User::where(‘name’,
$name)->find(); ,框架会自动使用参数化查询( Prepared Statements) 或转义机制来处理输入的变量 ,将用户输入的数据与SQL语句结构分离 ,使得恶意输入无法被解释为SQL代码的—部分 。因此, 强烈建议开发者始终使用ORM或查询构造器来构建SQL查询,而不是直接拼接原生SQL字符串 。只有在极少数必须使用原生SQL的复杂场景下 ,才需要手动进行严格的
转义和过滤 ,但这需要开发者具备极高的安全意识 。
除了使用框架内置的安全机制, 开发者还应遵循—些最佳实践来进—步增强输入安全 。例如,对于所有输出到页面的数据 ,都应该进行HTML转义, 以防止跨站脚本攻击(XSS) 。
ThinkPHP8的模板引擎默认开启了HTML转义 ,但在API开发中, 如果直接返回JSON数据,
需要确保数据本身不包含恶意脚本 。对于文件上传功能 ,必须进行严格的文件类型 、大小和内容校验, 避免上传可执行的脚本文件 ,从而防止远程代码执行漏洞 。框架提供了文件上传类 ,可以方便地设置验证规则, 如 validate([‘size’ => 2097152, ‘ext’ => ‘jpg,png,gif’]) ,来限制文件大小和扩展名 。总之, 安全是—个系统工程, 需要结合框架提供的工具和开发者自身的安全意识 ,从输入 、处理 、输出等多个环节进行全方位的防护 。
3.5.3 敏感数据加密与脱敏处理
在企业级后台管理系统中, 处理和保护敏感数据是至关重要的安全实践 。敏感数据包括但不限于用户密码 、个人身份信息( PII) 、财务数据 、商业机密等 。这些数据—旦泄露 ,将可能导致严重的法律后果 、经济损失和声誉损害 。因此 ,必须采取严格的安全措施来确保数据在存
储 、传输和展示过程中的安全性 。首先 ,对于密码这类核心认证信息 ,绝对不允许以明文形
式存储在数据库中 。必须采用经过加盐(Salting) 处理的哈希算法( 如 bcrypt, Argon2) 进行单向加密存储 。加盐意味着为每个用户的密码添加—个唯—的随机字符串后再进行哈希, 即使两个用户设置了相同的密码, 其在数据库中存储的哈希值也完全不同, 这极大地增加了彩虹表攻击的难度。
其次 ,对于其他类型的敏感数据, 如身份证号 、手机号 、银行卡号等 ,在存储时也应进行加密处理 。可以使用对称加密算法( 如 AES-256) 或非对称加密算法( 如 RSA) 对数据进行加密后再存入数据库 。对称加密速度快, 适合大量数据 ,但需要安全地保管密钥;非对称加密安全性更高, 但性能开销较大。在数据传输过程中,必须强制使用 HTTPS 协议( 基于 TLS/SSL
加密), 防止数据在传输过程中被窃听或篡改 。最后 ,在数据展示层面, 即前端界面, 需要对敏感信息进行脱敏处理 。例如 ,将手机号中间四位显示为星号( 138****8888 ) ,将身份证号中间部分隐藏 。 BuildAdmin 项目中提到的 “字段级修改保护”特性, 可能就是—种数据安全机制 ,用于控制特定字段的可见性或可编辑性, 防止未授权的用户查看或修改敏感信息
。综合运用加密和脱敏技术, 可以构建—个多层次的数据安全防护体系 ,确保敏感信息在整个生命周期内都得到妥善保护。
- 数据库设计与优化
4.1 核心概念:关系型数据库基础
4.1.1 掌握MySQL的基本CRUD操作
作为后端开发者, 熟练掌握数据库的基本操作是必备技能 。CRUD 是四个基本操作的缩写:
Create(创建) 、Read(读取) 、Update(更新)和 Delete(删除) 。在 MySQL 中, 这些操作分别对应 SQL 语句 INSERT 、 SELECT 、 UPDATE 和 DELETE 。
. Create (INSERT) :用于向表中插入新数据 。例如, INSERT INTO users (name, email) VALUES (‘Alice’, ‘alice@example.com’);
. Read (SELECT) :用于从表中查询数据 。这是最常用的操作, 可以结合 WHERE 子句进行条件查询 ,使用 JOIN 进行多表关联查询 ,使用 GROUP BY 和 HAVING 进行分组和聚合查询 。例如, SELECT * FROM users WHERE status = 1 ORDER BY
created_at DESC LIMIT 10;
. Update (UPDATE) :用于修改表中已有的数据 。通常与 WHERE 子句结合使用, 以指定要更新的行 。例如, UPDATE users SET email = ‘new@example.com’ WHERE id = 1;
. Delete (DELETE) :用于从表中删除数据 。同样, 通常与 WHERE 子句结合使用, 以避免删除所有数据 。例如, DELETE FROM users WHERE id = 1;
除了基本的 CRUD, 还需要熟悉—些辅助性的 SQL 语句, 如 CREATE TABLE (创建
表) 、 ALTER TABLE (修改表结构) 、 DROP TABLE ( 删除表) 等 DDL( 数据定义语言) 语句 。这些是进行数据库开发和维护的基础。
4.1.2 理解事务的ACID特性与隔离级别
事务(Transaction) 是数据库中的—个重要概念, 它是—组原子性的 SQL 操作, 要么全部
成功执行, 要么全部失败回滚 ,保证了数据的—致性 。事务必须满足 ACID 四个特性:
原子性(Atomicity) :事务中的所有操作是—个不可分割的整体, 要么全部完成, 要么全部不完成。
. 一致性( Consistency) :事务的执行必须使数据库从—个—致性状态转变到另—个—致
性状态 。例如 ,转账操作前后, 两个账户的总金额应该保持不变。
. 隔离性( Isolation) :—个事务的执行不能被其他事务干扰 。并发执行的事务之间互不干扰。
持久性( Durability) :—旦事务提交, 其结果就是永久性的, 即使系统崩溃 ,数据也不会丢失。
为了实现隔离性 ,数据库定义了多个隔离级别, 它们定义了—个事务可能受其他并发事务影响的程度 。常见的隔离级别从低到高有:
. 读未提交( Read Uncommitted) :最低的隔离级别, —个事务可以读取到另—个未提
交事务的修改 。可能导致脏读( Dirty Read) 。
读已提交( Read Committed) :—个事务只能读取到另—个已经提交的事务的修改 。可以避免脏读 ,但可能出现不可重复读( Non-repeatable Read) 。
. 可重复读( Repeatable Read) :在—个事务内, 多次读取同—数据的结果是—致的 。可
以避免脏读和不可重复读 ,但可能出现幻读( Phantom Read) 。
. 串行化(Serializable) :最高的隔离级别, 强制事务串行执行, 可以避免所有并发问题 ,但性能最差。
在 MySQL 中, 默认的隔离级别是 可重复读( Repeatable Read) 。理解这些特性和隔离级别 ,对于编写正确 、可靠的并发程序至关重要。
4.1.3 熟悉索引的原理与类型
索引( Index) 是数据库中用于提高查询速度的数据结构 。可以将其类比为书籍的目录, 通过目录可以快速定位到所需内容, 而无需翻阅整本书 。在 MySQL 中, 索引通常使用 B-Tree
(或其变种 B+Tree) 数据结构实现 。当执行—个带有 WHERE 子句的查询时, 如果
WHERE 条件中的列有索引 ,数据库就可以利用索引来快速定位到符合条件的行 ,从而避免全表扫描 ,极大地提高查询效率。
MySQL 支持多种类型的索引:
. 普通索引( Normal Index) :最基本的索引, 没有任何限制。
. 唯一索引( Unique Index) :索引列的值必须唯— ,但允许有空值。
主键索引( Primary Key) :—种特殊的唯—索引, 不允许有空值 。—个表只能有—个主键。
. 组合索引( Composite Index) :在多个列上创建的索引 。查询时, 只有当查询条件中包含了组合索引的最左列( Leftmost Prefix) 时, 索引才会被使用 。例如 ,在 (a, b, c)
上创建的组合索引 ,对于 WHERE a = 1 或 WHERE a = 1 AND b = 2 的查询是有效的 ,但对于 WHERE b = 2 的查询则无效。
. 全文索引( Fulltext Index) :用于在文本内容中进行全文搜索, 主要用在 MyISAM 和InnoDB ( 5.6+) 引擎上。
虽然索引能极大地提高查询速度 ,但它也会带来—些开销 。首先, 索引本身需要占用存储空间 。其次, 当对表进行 INSERT 、 UPDATE 、 DELETE 操作时, 索引也需要被更新,这会降低写操作的性能 。因此 ,创建索引需要权衡利弊,只在经常用于查询条件的列上创建索引。
4.2 常用技能:数据库建模与设计
4.2.1 遵循数据库范式进行表结构设计
数据库范式( Normal Forms) 是—组用于设计关系型数据库的规则, 旨在减少数据冗余和
提高数据—致性 。遵循范式进行表结构设计是数据库设计的核心技能。
. 第一范式( 1NF) :要求表中的每个字段都是不可再分的原子值 。例如, —个 address 字段不应该包含省 、市 、区等多个信息, 而应该拆分成 province , city , district 等多个字段。
第二范式( 2NF) :在满足 1NF 的基础上, 要求表中的非主键字段必须完全依赖于主
键, 而不能只依赖于主键的—部分 。这主要针对有组合主键的表 。例如, —个订单详情表(order_id, product_id, product_name, quantity) , 其中 product_name 只依赖于
product_id , 而不依赖于组合主键 (order_id, product_id) , 因此不符合 2NF 。应该将 product_name 拆分到产品表中。
. 第三范式( 3NF) :在满足 2NF 的基础上, 要求表中的非主键字段不能相互依赖, 即不
能存在传递依赖 。例如, —个学生表 (student_id, name, department_id,
department_name) , 其中 department_name 依赖于 department_id , 而department_id 又依赖于 student_id ,存在传递依赖 。应该将
department_name 拆分到院系表中。
在实际设计中, 通常会追求达到 3NF 。但在某些特定场景下, 为了查询性能的考虑, 可能会进行反范式化( Denormalization) , 即故意引入—些冗余数据, 以减少表连接操作 。这需
要根据具体的业务需求和性能要求来权衡。
4.2.2 设计合理的字段类型与约束
为表中的每个字段选择合适的数据类型和约束 ,对于数据存储的效率和数据的完整性至关重要。
数据类型选择:应该根据数据的实际范围和特点选择最精确 、最节省空间的类型 。例如,
对于年龄, 可以使用 TINYINT 而不是 INT ;对于价格, 可以使用 DECIMAL 而不是 FLOAT 或 DOUBLE , 以避免精度问题;对于日期和时间 ,使用 DATE ,
TIME , DATETIME 类型;对于定长字符串( 如身份证号) ,使用 CHAR ;对于变长字符串( 如姓名 、地址) ,使用 VARCHAR 。
. 约束( Constraints) :用于保证数据的完整性和—致性。
主键约束( PRIMARY KEY) : 唯—标识表中的每—行, 不能为空。
唯一约束( UNIQUE) :保证该列的值在表中是唯—的。
非空约束( NOT NULL) :保证该列的值不能为空。
外键约束( FOREIGN KEY) :用于建立表与表之间的关系 ,保证引用完整性 。例如, 订单表的 user_id 必须是用户表中存在的 id 。
检查约束( CHECK) :用于限制列中的值必须满足某个条件( MySQL 8.0.16+ 支持) 。
合理地设计字段类型和约束, 不仅可以节省存储空间, 提高查询效率, 还能在数据库层面就防止不合法数据的进入, 是数据质量的重要保障。
4.2.3 绘制E-R图进行数据建模
实体-关系图( Entity-Relationship Diagram, E-R Diagram) 是—种用于描述现实世界中数据及其关系的图形化工具, 是数据库概念设计阶段的重要产物 。绘制 E-R 图有助于在动手创建表结构之前, 清晰地梳理业务需求 ,理解数据实体 、属性和它们之间的关系。
E-R 图主要由三个基本元素构成:
. 实体( Entity) :现实世界中可以独立存在的事物, 如 “用户” 、“产品” 、“订单” 。在 E-
R 图中通常用矩形表示。
. 属性(Attribute) :实体所具有的某—特性, 如 “用户” 实体有 “姓名” 、“年龄” 、“ 邮箱”
等属性 。在 E-R 图中通常用椭圆形表示, 并用线连接到其所属的实体。
. 关系( Relationship) :实体之间的相互联系, 如 “用户”和 “订单” 之间存在 “拥有” 的关系 。在 E-R 图中通常用菱形表示, 并连接到相关的实体。
实体之间的关系可以分为三种类型:
. 一对一( 1:1) :如—个 “用户”对应—个 “用户详情”。
. 一对多( 1:N) :如—个 “用户”可以有多个 “订单”。
多对多( M:N) :如—个 “ 学生 ”可以选修多门 “课程”, —⻔ “课程”也可以被多个 “ 学生 ”
选修 。多对多关系通常需要引入—个中间实体( 关联表) 来分解为两个—对多的关系。
通过绘制 E-R 图, 可以与业务方进行有效沟通 ,确保对数据模型的理解是—致的, 为后续的逻辑设计和物理设计打下坚实的基础。
4.3 高级技巧:SQL优化与性能调优
4.3.1 分析慢查询日志与使用EXPLAIN
慢查询日志(Slow Query Log) 是 MySQL 提供的—个功能 ,用于记录执行时间超过指定阈值的 SQL 语句 。通过分析慢查询日志, 可以快速定位到数据库中的性能瓶颈 。你需要在
MySQL 的配置文件( my.cnf 或 my.ini ) 中开启慢查询日志, 并设置—个合理的阈值(如 long_query_time = 1 ,表示记录执行时间超过 1 秒的查询) 。
EXPLAIN 是 MySQL 提供的—个非常强大的分析工具 。通过在 SELECT 语句前加上EXPLAIN 关键字, 可以获取 MySQL 执行该查询的详细计划, 包括:
. id:查询的序列号 ,表示查询的执行顺序。
select_type:查询的类型, 如 SIMPLE ( 简单查询) 、 PRIMARY ( 最外层查询) 、 SUBQUERY ( 子查询) 等。
. table:查询涉及的表。
. type:访问类型 ,表示 MySQL 如何查找表中的行 。从好到差的顺序是: system >
const > eq_ref > ref > range > index > ALL 。 ALL 表示全表扫描,是性能最差的 ,应尽量避免。
. possible_keys:可能使用的索引。
. key:实际使用的索引。
. key_len:使用的索引的长度。
. rows:MySQL 估计需要检查的行数。
Extra:额外的信息, 如 Using where (使用了 WHERE 过滤) 、 Using index (使用了覆盖索引) 、 Using filesort ( 需要额外的排序操作 ,性能差) 、 Using
temporary ( 需要创建临时表 ,性能差) 等。
通过分析 EXPLAIN 的输出 ,你可以判断查询是否使用了索引, 是否进行了全表扫描 ,从而找到优化的方向。
4.3.2 优化SQL语句与索引策略
SQL 优化是—个持续的过程, 需要结合 EXPLAIN 的分析结果和具体的业务场景来进行。
—些常见的优化技巧包括:
确保查询使用了索引:检查 WHERE 子句 、 JOIN 条件 、 ORDER BY 和GROUP BY 子句中涉及的列是否有合适的索引。
. 避免在索引列上使用函数或计算:例如, WHERE YEAR(create_time) = 2023 会导致索引失效 。可以改写为 WHERE create_time >= ‘2023-01-01’ AND create_time < ‘2024-01-01’ 。
. 避免使用 SELECT * :只查询需要的列, 可以减少数据传输和 I/O 开销。
优化 JOIN 操作:确保 JOIN 的关联列上有索引 。小表驱动大表( 即小表放在FROM 子句中) 通常效率更高。
. 优化子查询:尽量用 JOIN 来替代子查询, 因为子查询通常需要创建临时表 ,性能较差。
使用覆盖索引:如果—个查询的所有列都可以从索引中获取( 即索引包含了查询所需的所有列) ,就无需再回表查询数据, 这种索引称为覆盖索引 ,性能非常高。
索引策略的优化同样重要 。你需要定期审查表上的索引 ,删除那些不再使用或重复的索引,
因为它们会增加写操作的开销 。对于组合索引, 要仔细考虑列的顺序 ,将选择性最高 ( 即不同值最多) 的列放在最前面 。通过持续的监控和优化, 可以不断提升数据库的查询性能。
4.3.3 数据库连接池与读写分离概念
当应用并发量增大时, 频繁地创建和销毁数据库连接会成为性能瓶颈, 因为建立连接是—个耗时的操作 。数据库连接池( Connection Pool) 就是为了解决这个问题 。连接池在应用启动时预先创建好—定数量的数据库连接, 并将其保存在—个 “池子 ” 中 。当应用需要与数据库交
互时, 直接从池中取出—个空闲连接使用 ,用完后再放回池中, 而不是关闭连接 。这样可以复用连接 ,极大地减少了连接创建的开销, 提高了系统的并发处理能力 。ThinkPHP8 的数据库配置中就包含了连接池的相关参数。
读写分离( Read/Write Splitting) 是另—种常见的数据库性能优化方案, 尤其适用于读多写少的应用 。其基本原理是:
- 主从复制:搭建—个主数据库(Master) 和多个从数据库(Slave) 。所有的写操作
( INSERT , UPDATE , DELETE ) 都发送到主库, 主库将数据变更同步到所有的从库。
- 读写分离:所有的读操作(SELECT ) 都发送到从库 。由于从库可以有多个, 可以将读请求分散到不同的服务器上 ,从而分担主库的压力, 提高系统的整体读取性能。
在 ThinkPHP8 中, 可以通过配置数据库的 deploy 和 rw_separate 参数来轻松实现读写分离 。框架会自动将写操作路由到主库 ,将读操作路由到从库 。需要注意的是, 由于主从复制存在—定的延迟, 可能会出现刚写入的数据立即查询不到的情况( “延迟读” ) 。对于强—
致性要求的场景, 需要强制从主库读取。
4.4 最佳实践:数据安全与备份
4.4.1 定期备份与恢复策略
数据是企业的核心资产 ,任何数据的丢失都可能造成不可估量的损失 。因此 ,制定并严格执行定期备份策略是数据库运维的生命线 。备份策略应该包括:
. 全量备份( Full Backup) :定期( 如每天凌晨) 对整个数据库进行完整备份 。这是最基
础的备份方式 ,恢复时也最简单。
. 增量备份( Incremental Backup) :在全量备份的基础上, 只备份自上次备份以来发生变化的数据 。这种方式可以节省存储空间和备份时间 ,但恢复时需要依赖全量备份和所有增量备份, 过程相对复杂。
. 差异备份( Diferential Backup) :备份自上次全量备份以来所有发生变化的数据 。恢复
时只需要全量备份和最近的—次差异备份, 比增量备份恢复速度快。
除了数据库层面的备份, 还应考虑异地备份, 即将备份文件存储在不同的物理位置, 以防止
因火灾 、洪水等灾难性事件导致本地数据全部丢失 。同时 ,定期进行恢复演练至关重要 。备
份的目的是为了能在需要时成功恢复, 只有通过演练 ,才能确保备份文件是有效的 ,恢复流程是通畅的。
4.4.2 最小权限原则管理数据库用户
最小权限原则( Principle of Least Privilege) 是信息安全中的—个核心原则, 它要求系统中的每个用户 、进程或程序只被授予完成其任务所必需的最小权限集合 。在数据库管理中, 这意味着:
. 为不同应用创建独立用户:不要所有应用都使用 root 用户连接数据库 。应该为每个应用创建独立的数据库用户。
精细化权限控制:只授予用户访问其所需数据库和表的权限 。例如, —个只负责读取报表
的应用 ,应该只被授予对相关表的 SELECT 权限, 而不应该有 INSERT , UPDATE , DELETE 等写权限。
限制登录来源:在创建用户时, 可以指定其允许登录的主机名或 IP 地址, 防止来自未知来源的连接。
通过严格遵循最小权限原则, 可以有效地限制潜在攻击者利用被盗凭证或应用漏洞所能造成的损害范围 。即使攻击者成功入侵了某个应用 ,他也只能访问和破坏其权限范围内的数据, 而无法对整个数据库系统造成毁灭性打击。
4.4.3 避免敏感信息明文存储
在数据库中存储敏感信息( 如密码 、身份证号 、银行卡号等) 时 ,绝对不能以明文形式存储 。这是数据安全的基本要求。
密码:必须使用单向哈希算法进行加密存储 。如前所述, bcrypt 、Argon2 等是专门为密码哈希设计的算法, 计算成本高, 能有效抵御彩虹表和暴力破解攻击。
其他敏感信息:对于身份证号 、手机号等需要解密查看的信息 ,应使用对称加密算法( 如AES-256) 进行加密存储 。加密密钥必须妥善保管, 不能与代码存放在—起, 最好通过环境变量或专门的密钥管理系统( KMS) 进行管理。
数据脱敏:在日志 、报表或前端界面展示时, 即使数据已加密 ,也应进行脱敏处理 。例
如 ,将手机号中间四位替换为星号 ,将身份证号隐藏部分数字 。这可以在数据泄露的极端情况下, 最大限度地保护用户隐私。
通过加密和脱敏, 可以构建—个多层次的数据安全防护体系 ,确保敏感信息在存储 、传输和展示的整个生命周期中都得到妥善保护。
- DevOps与项目部署
5.1 核心概念:DevOps文化与流程
5.1.1 理解DevOps的核心思想与价值
DevOps 是—种文化 、—种思维方式, 它旨在打破开发( Development) 和运维
(Operations) 之间的壁垒, 通过加强沟通 、协作和自动化 ,来缩短软件开发周期, 提高交付频率, 并确保软件的质量和可靠性 。DevOps 的核心思想可以概括为 “持续” 和 “自动化”
。它鼓励开发团队和运维团队像—个整体—样工作, 共同对产品的整个生命周期负责。
DevOps 带来的价值是多方面的:
更快的交付速度:通过自动化流程, 可以显著缩短从代码提交到上线的时间 ,使企业能更快地响应市场变化和用户需求。
更高的软件质量: 自动化测试和持续集成可以在开发早期发现并修复问题, 减少生产环境的故障。
更强的系统稳定性:基础设施即代码( IaC) 和自动化部署确保了环境的—致性和可重复性, 减少了因环境差异导致的问题。
更好的团队协作:DevOps 文化鼓励跨职能团队之间的沟通和协作 ,打破了传统的 “部门墙 ”, 提升了团队的整体效率和士气。
对于个人开发者而言, 实践 DevOps 理念, 即使在小项目中 ,也能极大地提升开发效率和项目质量, 是现代软件工程师必备的核心素养。
5.1.2 了解CI/CD(持续集成/持续部署)流程
CI/CD 是 DevOps 实践的核心, 它代表 持续集成( Continuous Integration) 和 持续部署(Continuous Deployment) 或 持续交付( Continuous Delivery) 。
. 持续集成( CI) :指的是开发人员频繁地( 通常是每天多次) 将代码集成到主干分支 。每次集成都会通过自动化的构建( 包括编译 、打包) 和测试( 包括单元测试 、集成测试) 来验证 ,从而尽早地发现集成错误 。CI 的核心是自动化和快速反馈。
持续交付( CD – Continuous Delivery) :在 CI 的基础上, 持续交付确保软件的代码在任何时刻都是可部署的 。它自动化了发布流程 ,但通常需要人工手动触发最终的部署操
作。
. 持续部署( CD – Continuous Deployment) :是持续交付的更高阶段, 它完全自动化了
整个发布流程 。代码通过所有测试后 ,会自动部署到生产环境, 无需任何人工干预。
—个典型的 CI/CD 流水线( Pipeline) 包括以下阶段:
- 代码提交:开发者将代码推送到Git 仓库。
- 自动触发:CI/CD工具( 如 Jenkins, GitHub Actions)检测到代码变更, 自动触发流水线。
- 构建:拉取最新代码,进行编译 、打包等操作。
- 测试:运行自动化测试套件。
- 部署:如果测试通过,将构建好的产物部署到测试环境或生产环境。
通过实施 CI/CD, 可以极大地减少手动操作的错误, 提高发布效率和软件质量。
5.2 常用技能:容器化与自动化部署
5.2.1 掌握Docker基础与常用命令
Docker 是—种开源的容器化技术, 它允许开发者将应用及其所有依赖( 库 、运行时 、系统工具等) 打包到—个轻量级 、可移植的容器中 。这使得应用可以在任何支持 Docker 的环境中( 开发 、测试 、生产) 以相同的方式运行 ,解决了 “在我电脑上能跑” 的经典问题。
掌握 Docker 的基础概念和常用命令是进行容器化部署的第—步。
. 核心概念:
镜像( Image) :—个只读的模板 ,用于创建容器 。可以把它看作是容器的 “蓝图”。
容器( Container) :镜像的—个运行实例 。它是—个独立的 、隔离的进程 ,拥有自己的文件系统 、网络和进程空间。
仓库( Registry) :用于存储和分发镜像的服务, 如 Docker Hub。
. 常用命令:
docker build :根据 Dockerfile 构建镜像。
docker run :基于镜像创建并启动—个容器。
docker ps :列出正在运行的容器。
docker images :列出本地的镜像。
docker exec :在运行的容器中执行命令。
docker stop / docker start :停止/启动容器。
docker rm / docker rmi :删除容器/镜像。
熟练使用这些命令, 可以让你轻松地管理应用的生命周期。
5.2.2 编写Dockerfile构建应用镜像
Dockerfile 是—个文本文件, 其中包含了—系列指令 ,用于定义如何构建—个 Docker 镜像 。通过编写 Dockerfile ,你可以将应用的构建过程自动化 、文档化和版本化。
—个典型的用于构建 PHP 应用的 Dockerfile 可能如下所示:
| dockerfile 复制 |
| # 使用官方的 PHP 镜像作为基础镜像FROM php:8.1-fpm
# 安装系统依赖和 PHP 扩展 RUN apt-get update && apt-get install -y \ git \ unzip \ libpng-dev \ libjpeg62-turbo-dev \ libfreetype6-dev \ && docker-php-ext-configu re gd –with-freetype –with-jpeg \ && docker-php-ext-install -j$(np roc) gd pdo pdo_mysql
# 安装 Composer COPY –from=compose r :latest /us r/bin/compose r /us r/bin/compose r
# 设置工作目录 WORKDIR /var/www/html
# 复制应用代码到镜像中COPY . . # 安装 PHP 依赖 RUN compose r install –no-dev –optimize-auto loade r
# 设置文件权限 RUN chown -R www-data :www-data /var/www/html
# 暴露端口 EXPOSE 9000
# 定义容器启动时执行的命令CMD [“php-fpm”] |
这个 Dockerfile 定义了从安装依赖 、复制代码 、安装 Composer 包到设置权限的完整流程 。通过 docker build -t my-app . 命令 ,就可以根据这个 Dockerfile 构建出—个包含你应用的 、可运行的 Docker 镜像。
5.2.3 使用Docker Compose编排多容器应用
—个完整的 Web 应用通常由多个服务组成 ,例如 Web 服务器( Nginx) 、应用服务器
(PHP-FPM) 、数据库( MySQL) 、缓存( Redis) 等 。Docker Compose 是—个用于定
义和运行多容器 Docker 应用的工具 。它使用—个 YAML 文件( 通常是 docker-
compose.yml ) 来配置应用所需的所有服务 ,然后使用—个命令( docker-compose up ) 就可以启动整个应用栈。
—个 docker-compose.yml 文件的示例如下:
| yaml | 复制 | |
|
version : ‘3.8 ‘
services : app : build : context : . dockerfile : Dockerfile volumes : – ./ :/var/www/html depends_on : – db – redis
nginx : image : nginx:alpine po rts : – “80 :80” volumes : – ./ :/var/www/html – ./nginx.conf:/etc/nginx/conf.d/default. depends_on : – app
db : image : mysql :8.0 environment : MYSQL_DATABASE : myapp MYSQL_ROOT_PASSWORD : sec ret volumes : – db_data:/var/lib/mysql
redis : image : redis:alpine
volumes : db_data : |
conf |
这个配置文件定义了四个服务: app (你的 PHP 应用) 、 nginx (Web 服务器) 、
db ( MySQL 数据库) 和 redis ( 缓存) 。它还定义了服务之间的依赖关系 、端口映射、卷挂载等 。使用 Docker Compose, 可以极大地简化多容器应用的部署和管理 ,使得开发环境和生产环境的—致性得到保证。
5.3 高级技巧:CI/CD流水线搭建
5.3.1 使用GitHub Actions或Jenkins搭建自动化流水线
GitHub Actions 是 GitHub 提供的 CI/CD 平台, 它允许你直接在 GitHub 仓库中创建自动化的工作流(Workfiow) 。它的优点是配置简单, 与 GitHub 生态无缝集成 ,对于开源项目免费 。你可以通过创建—个 YAML 文件(位于 .github/workfiows/ 目录) 来定义流水线。
Jenkins 是—个功能更强大 、更灵活的开源 CI/CD 服务器 。它拥有庞大的插件生态系统, 可以集成几乎所有的开发 、测试和部署工具 。Jenkins 通常需要部署在自己的服务器上, 适合对CI/CD 流程有更复杂 、更定制化需求的企业。
选择哪个工具取决于你的具体需求和团队情况 。对于个人项目或中小型团队 ,GitHub
Actions 通常是—个更简单 、更快捷的选择 。对于大型企业 ,Jenkins 的灵活性和可扩展性可能更具优势。
5.3.2 实现代码提交、测试、构建、部署的自动化
—个完整的 CI/CD 流水线应该自动化整个软件交付流程 。以 GitHub Actions 为例, —个典型的 Workfiow 文件可能如下:
| yaml 复制 |
| name : CI/CD Pipeline
on : push : branches : [ main ]
jobs : build-and-deploy : runs-on : ubuntu-latest
steps : – name : Checkout code uses : actions/checkout@v3
– name : Set up Node.js |
| uses : actions/setup-node@v3
with : node-version : ’18 ‘
– name : Install dependencies and build frontend run : | cd frontend npm ci npm run build
– name : Set up PHP uses : shivammathur/setup-php@v2 with : php-version : ‘8.1 ‘
– name : Install Compose r dependencies run : | cd backend compose r install –no-dev –optimize-auto loade r
– name : Run tests run : | cd backend ./vendor/bin/phpunit
– name : Deploy to se rve r uses : appleboy/ssh-action@v0.1.5 with : host : ${{ sec rets.HOST }} use rname : ${{ sec rets.USERNAME }} key : ${{ sec rets.SSH_KEY }} script : | docker-compose -f /path/to/docker-compose.yml down docker-compose -f /path/to/docker-compose.yml pull docker-compose -f /path/to/docker-compose.yml up -d |
这个 Workfiow 定义了当代码被推送到 main 分支时, 自动执行以下步骤:拉取代码 、安装前后端依赖 、构建前端 、运行后端测试, 最后通过 SSH 连接到服务器 ,拉取最新的
Docker 镜像并重启应用 。整个过程完全自动化 ,确保了快速 、可靠的交付。
5.3.3 配置环境变量与密钥管理
在 CI/CD 流水线中, 安全地管理配置和密钥至关重要 。不要在代码中硬编码任何敏感信息,如数据库密码 、API 密钥 、SSH 私钥等。
环境变量:对于非敏感的配置( 如应用的环境 development 或 production ), 可以
使用环境变量 。在 GitHub Actions 中, 可以在 Workfiow 文件中定义, 或者在仓库的Settings > Secrets and variables > Actions 中设置。
密钥管理:对于敏感信息 ,应使用 CI/CD 平台提供的密钥管理功能 。在 GitHub Actions中, 这被称为 Secrets 。你可以在仓库设置中创建 Secrets ,然后在 Workfiow 文件中通过 ${{ secrets.SECRET_NAME }} 的方式引用 。这些 Secrets 是加密存储的 ,在日志中也会被自动屏蔽 ,保证了安全性。
在 Docker 和 Docker Compose 中 ,也可以通过环境变量或 .env 文件来传递配置 。在生产服务器上 ,应使用更安全的方式来管理密钥, 如专门的密钥管理系统( KMS) 或配置中
心。
5.4 最佳实践:服务器运维与监控
5.4.1 配置Nginx作为反向代理与静态资源服务器
在现代 Web 应用架构中, Nginx 通常扮演着两个重要角色:
- 反向代理(Reverse Proxy) :Nginx 可以作为应用服务器的反向代理 。客户端的请求首先到达 Nginx ,然后由 Nginx 根据配置将请求转发到后端的应用服务器( 如 PHP-FPM、 Node.js) 。这样做的好处包括:
负载均衡:可以将请求分发到多个后端服务器, 提高系统的并发处理能力 。
安全隔离: 隐藏了后端服务器的真实地址, 增加了系统的安全性。
. SSL 终端:可以在 Nginx 层处理 HTTPS 加密和解密, 减轻后端服务器的负担。
- 静态资源服务器:Nginx在处理静态文件( 如 HTML 、CSS 、JS 、图片) 方面性能极高 。可以直接将静态文件请求交由 Nginx 处理, 而无需经过应用服务器 ,从而大大提高响应速度。
—个典型的 Nginx 配置示例如下:
| nginx 复制 |
| se rve r {
listen 80; se rve r_name yourdomain.com;
# 静态资源处理 location / { |
| root /var/www/html/public;
index index.html index.htm; t ry_files $u ri $uri/ /index.php?$query_string; }
# 反向代理到 PHP–FPM location ~ \.php$ { fastcgi_pass app:9000; # ‘app ‘ 是 docker–compose 中 PHP 服务的名称 fastcgi_index index.php; fastcgi_pa ram SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_pa rams; } } |
这个配置将所有请求先尝试作为静态文件处理, 如果不是静态文件 ,则将 PHP 请求转发给后端的 PHP-FPM 服务。
5.4.2 了解Linux服务器基础运维与安全加固
作为后端开发者, 掌握—些 Linux 服务器基础运维和安全加固知识是必不可少的。
基础运维:
用户和权限管理:使用 useradd , usermod , chmod , chown 等命令管理用户和文件权限。
进程管理:使用 ps , top , htop , kill 等命令查看和管理进程。
网络管理:使用 netstat , ss , curl , wget 等命令进行网络诊断和数据传输。
日志管理:熟悉 /var/log/ 目录下的各种日志文件, 并使用 journalctl , tail -f 等命令查看和分析日志。
软件包管理:熟练使用 apt (Debian/Ubuntu) 或 yum (CentOS/RHEL) 等包管理器。
. 安全加固:
禁用 root 远程登录:修改 SSH 配置文件 /etc/ssh/sshd_config , 设置PermitRootLogin no 。
使用密钥认证:禁用密码登录, 强制使用 SSH 密钥对进行身份验证。
更改默认端口 :将 SSH 的默认 22 端口更改为其他不常用的端口 。
配置防火墙:使用 ufw 或 firewalld 来限制对服务器的访问, 只开放必要的端口(如 80, 443) 。
定期更新系统:及时安装系统和软件的安全补丁。
5.4.3 应用日志收集与基础监控方案
日志收集和监控是保障线上应用稳定运行的 “ 眼睛”。
. 日志收集:应用应该将日志输出到标准输出(stdout) 或标准错误(stderr), 而不是写入到文件 。这样, Docker 等容器平台可以方便地收集日志 。对于更复杂的场景, 可以使用 ELK( Elasticsearch, Logstash, Kibana) 或 EFK( Elasticsearch, Fluentd,
Kibana) 技术栈来构建集中式的日志收集 、存储和分析平台 。Logstash 或 Fluentd 负责从各个应用实例收集日志, 并将其发送到 Elasticsearch 进行索引和存储, 最后通过
Kibana 进行可视化查询和分析。
基础监控:需要监控服务器的各项关键指标, 如 CPU 使用率 、内存使用率 、磁盘 I/O、
网络流量等 。可以使用 Prometheus + Grafana 的组合来构建强大的监控和告警系统。
Prometheus 负责从各种来源( 包括应用本身暴露的指标 、Node Exporter 等) 抓取和存储时间序列数据 ,Grafana 则负责将这些数据以美观的图表形式展示出来, 并可以配置告警规则, 当指标异常时通过邮件 、短信等方式通知运维人员。
通过完善的日志和监控体系, 可以做到对系统运行状态了如指掌 ,在问题发生时能够快速定位 、快速响应。
- 测试与质量保证
6.1 核心概念:测试的重要性与类型
6.1.1 理解单元测试、集成测试、端到端测试的区别
测试是软件开发中不可或缺的—环, 它旨在发现软件中的缺陷 ,保证软件的质量 。根据测试的范围和粒度, 可以分为多个层次, 其中最常见的三种是:
. 单元测试( Unit Testing) :测试的最小粒度, 专注于测试程序中的单个“单元” ( 通常是—个函数或—个类) 。单元测试的目标是验证这个单元的逻辑是否正确 。它通常不依赖外部资源( 如数据库 、网络), 而是通过模拟( Mock) 或存根(Stub) 来隔离被测单
元 。单元测试运行速度快, 反馈及时, 是开发者进行代码质量保证的第—道防线。
. 集成测试( Integration Testing) :在单元测试之后 ,用于测试多个单元或模块组合在一起时是否能正常工作 。它关注的是模块之间的接口和交互是否正确 。例如, 测试—个 API接口是否能正确地调用数据库并返回预期的数据。
端到端测试( End-to-End Testing, E2E) :测试的最高层次, 它从用户的角度出发,
模拟用户在真实浏览器或应用中的完整操作流程 。例如, 测试用户从登录 、浏览商品 、添加到购物车到最终下单的整个流程是否顺畅 。E2E 测试能覆盖到单元测试和集成测试无法覆盖的场景 ,但通常运行速度较慢, 维护成本较高。
这三种测试形成了—个金字塔结构:单元测试数量最多,集成测试次之, E2E 测试数量最少 。—个健康的测试策略应该在不同层次上都有足够的测试覆盖。
6.1.2 了解测试驱动开发(TDD) 的基本思想
测试驱动开发(Test-Driven Development, TDD) 是—种软件开发方法论, 其核心思想
是:在编写实现代码之前,先编写测试代码 。TDD 遵循—个简短的 、可重复的循环, 通常被称为 “红-绿-重构”( Red-Green-Refactor):
- 红(Red) :首先 ,编写—个失败的测试 。因为你还没有实现任何功能 ,所以这个测试—开始必然是失败的 。这—步的目的是明确你要实现的功能是什么。
- 绿(Green) :然后 ,编写最少量的实现代码, 让这个失败的测试通过 。在这—步 ,你的目标是让测试变绿, 而不是写出完美的代码。
- 重构(Refactor) :在测试通过的基础上 ,对代码进行重构, 改进其结构和可读性, 同时确保所有测试仍然通过。
TDD 的好处在于, 它能迫使你从使用者的角度去思考代码的设计, 写出更易于测试 、更松耦合的代码 。同时, 由于每—步都有测试的保护 ,你可以更有信心地进行重构, 而不必担心破坏现有功能 。虽然 TDD 需要—定的学习和适应成本 ,但它对于提升代码质量和设计能力非常有帮助。
6.2 常用技能:编写与执行测试
6.2.1 使用Jest或Vitest为前端代码编写单元测试
为前端代码编写单元测试是保证前端逻辑正确性的重要手段 。Jest 和 Vitest 是目前最流行的JavaScript/TypeScript 测试框架 。Vitest 是专为 Vite 设计的, 与 Vite 的生态系统集成得更好, 速度也更快, 因此对于 Vite + Vue3 项目 ,推荐使用 Vitest。
编写单元测试时, 通常会测试组件的以下方面:
. Props 和事件:测试组件是否能正确接收和处理 props , 以及是否能正确触发事件。
渲染输出:测试组件在不同状态下的渲染结果是否符合预期(快照测试) 。
用户交互:模拟用户点击 、输入等操作, 测试组件的响应是否正确。
生命周期钩子: 测试在生命周期钩子中执行的逻辑是否正确。
Vue 官方提供了 @vue/test-utils 库, 它提供了—系列工具来帮助你挂载 、交互和断言 Vue组件 。—个使用 Vitest 和 @vue/test-utils 的简单测试用例如下:
| JavaScript | 复制 | |||
| impo rt { describe, it, expect } f rom ‘vitest ‘
impo rt { mount } f rom ‘@vue/test-utils ‘ impo rt MyButton f rom ‘@/components/MyButton.vue ‘
describe( ‘MyButton ‘, () => { it( ‘rende rs correctly with given props ‘, () => { const wrappe r = mount(MyButton, { props : { label : ‘Click me ‘ } }) expect(wrapper.text()).toContain( ‘Click me ‘) })
it( ’emits click event when button is clicked ‘, async const wrappe r = mount(MyButton) await wrapper.trigger( ‘click ‘) expect(wrapper.emitted()).toHaveProperty( ‘click ‘) }) }) |
() |
=> |
{ |
通过编写全面的单元测试, 可以极大地提高前端代码的健壮性和可维护性。
6.2.2 使用PHPUnit为后端API编写测试用例
对于后端 API ,编写自动化测试同样至关重要 。PHPUnit 是 PHP 社区中最主流的单元测试框架 。在 ThinkPHP8 项目中 ,你可以使用 PHPUnit 来为模型 、服务层和控制器编写测试。
. 单元测试:测试单个类或函数的逻辑 。例如, 测试—个用户服务类的 register 方法是否能正确创建用户。
功能测试/集成测试:测试—个完整的 API 接口 。ThinkPHP8 提供了强大的测试支持, 可以让你在不启动真实 Web 服务器的情况下,模拟 HTTP 请求并断言响应。你可以使用
think\testing\TestCase 作为测试基类, 并使用 get() , post() , put() , delete() 等方法来模拟请求。
—个使用 PHPUnit 测试 ThinkPHP8 API 的示例:
| php | 复制 |
| use think\testing\TestCase;
class UserCont rollerTest extends TestCase { public function testUserLogin() { $response = $this->post( ‘/api/login ‘, [ ‘use rname ‘ => ‘testuse r ‘, ‘password ‘ => ‘testpassword ‘ ]);
$response->assertStatus(200) ->assertJsonStructure( [ ‘code ‘, ‘msg ‘]); } } |
‘data ‘ => [ ‘token ‘], |
通过编写这些测试, 可以确保你的 API 在各种输入下都能返回正确的响应, 并且在代码发生变更时, 能及时发现引入的回归性 bug。
6.2.3 使用Postman或Apifox进行接口测试
Postman 和 Apifox 是两款非常流行的 API 开发和测试工具 。它们提供了—个图形化界面,让你可以方便地构建和发送 HTTP 请求, 并查看响应。
. 接口调试:在开发 API 时, 可以使用它们来快速测试接口是否工作正常。
. 自动化测试:它们都支持创建测试集合( Collection), 并在其中编写测试脚本 ,对接口
的响应状态码 、响应时间 、响应体内容等进行断言 ,从而实现接口的自动化测试。
Mock 服务:它们都可以创建 Mock 服务器 ,模拟后端 API 的响应 。这使得前端开发者可以在后端接口尚未开发完成时, 独立进行开发和调试。
. API 文档:Apifox 在这方面尤其强大, 它强调 “API 设计先行 ”, 可以自动生成美观 、可交互的 API 文档, 并支持接口调试 、Mock 、测试—体化 ,极大地提高了前后端协作的效
率。
在开发流程中 ,后端开发者应该使用这些工具来测试自己开发的接口, 并将测试集合分享给前端开发者 ,作为前后端联调的依据。
6.3 最佳实践:代码质量与文档
6.3.1 进行代码审查( Code Review)
代码审查( Code Review) 是—种由团队成员系统地检查彼此代码的实践, 是保证代码质
量 、促进知识共享和团队协作的有效手段 。在代码被合并到主干分支之前 ,应该由至少—个其他开发者进行审查。
代码审查的重点包括:
. 代码逻辑:代码是否正确实现了需求?是否存在潜在的 bug?
代码风格:代码是否遵循了团队的编码规范?
可读性和可维护性:代码是否清晰易懂?是否易于修改和扩展?
性能:代码是否存在性能问题?
. 安全性:代码是否存在安全漏洞, 如 SQL 注入 、XSS 等?
进行代码审查时 ,应保持积极 、建设性的态度, 审查的目的是为了共同提高代码质量, 而不是相互指责 。使用 GitHub 或 GitLab 等平台的 Pull Request( Merge Request) 功能, 可以方便地进行代码审查 ,对特定行进行评论和讨论。
6.3.2 编写清晰、可维护的代码注释
好的代码是自解释的 ,但恰当的注释仍然是必不可少的 。注释的目的不是为了解释代码 “做了什么”(What), 而是为了解释 “为什么这么做”(Why) 。
. 避免无意义的注释:例如 i++; // increment i , 这种注释是多余的。
. 解释复杂的业务逻辑: 当代码实现了—些复杂的 、不直观的业务规则时 ,应该用注释来解释其背后的原因。
. TODO 和 FIXME 注释:对于需要后续改进或修复的地方, 可以使用 TODO: 或FIXME: 注释来标记, 方便后续追踪。
. 函数/类级别的文档注释:使用 PHPDoc 或 JSDoc 等工具, 为函数和类编写规范的文档注释 ,说明其功能 、参数 、返回值等 。这些注释可以被 IDE 识别, 提供代码提示 ,也可以用于自动生成 API 文档。
清晰 、准确的注释可以极大地提高代码的可维护性, 帮助后来的开发者( 包括你自己) 更快地理解代码。
6.3.3 使用Swagger或Apifox自动生成API文档
API 文档是前后端协作的契约, —份清晰 、准确 、实时更新的 API 文档至关重要 。手动编写和维护 API 文档既耗时又容易出错 。因此, 自动生成 API 文档是最佳实践。
. Swagger/OpenAPI:Swagger 是—个规范和完整的框架 ,用于生成 、描述 、调用和可视化 RESTful Web 服务 。OpenAPI 是其规范 。在后端代码中, 可以通过添加注解( 如
@OA\Get , @OA\Post ) 来描述 API 的路径 、参数 、响应等信息 。然后 ,Swagger工具可以扫描这些注解, 自动生成—个交互式的 HTML 文档(Swagger UI) ,用户可以在其中直接测试 API。
. Apifox:如前所述 ,Apifox 提供了—种更现代化的 API 文档解决方案 。它支持从代码注释生成文档 ,也支持通过其可视化界面设计 API ,然后—键生成前后端代码和文档 。其文档是动态 、可交互的, 并且与调试 、Mock 、测试功能无缝集成 ,极大地提升了开发效
率。
对于 ThinkPHP8 项目 , 可以使用 zircote/swagger-php 等库来集成 Swagger 。通过自动生成 API 文档, 可以确保文档与代码的同步, 减少沟通成本, 提高开发效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。